A VTK pipeline primer (part 1)

In my last two blogs (1, 2), I introduced the vtkPythonAlgorithm and started demonstrating how it can be used to develop sources and algorithms in Python. In those articles, I touched on a few VTK pipeline concepts. For those are not familiar with VTK’s pipeline, this may have been somewhat hard to follow. So in this article and the next, I will take a step back and explain how VTK’s pipeline works in more detail.
Preliminaries
vtkInformation and vtkInformationVector
These two classes are used all over the VTK: in algorithms, in executives, in data objects. They were developed by Brad King when we overhauled the VTK pipeline in VTK 4. Conceptually, they are simply maps. The key is a pointer to an instance of a vtkInformationKey (or of a subclass) and the value is an instance of vtkObjectBase (or of a subclass). Let’s start with an example.
import vtk from vtk.util import keys key = keys.MakeKey(keys.ObjectBaseKey, "a new key", "some class") print "key:\n", key info = vtk.vtkInformation() print "info:\n", info key.Set(info, vtk.vtkObject()) print "info after set:\n", info
This will print the following.
key: vtkInformationObjectBaseKey (0x7f8390698680) Reference Count: 1 info: vtkInformation (0x7f8390466ff0) Debug: Off Modified Time: 51 Reference Count: 1 Registered Events: (none) info after set: vtkInformation (0x7f8390466ff0) Debug: Off Modified Time: 54 Reference Count: 1 Registered Events: (none) a new key: vtkObject(0x7f839069b130)
On line 4, we created a new key type. Most often you will use existing keys but it is useful to know how to create them. This key has a name a new key and location some class. The latter is usually the name of the class this key is accessed from. More on that later. One line 7, we create an empty information object. On line 10, we add a new vtkObject to the information object. Not that line 10 looks backwards and it feels more natural to do the following instead.
info.Set(key, vtk.vtkObject())
Both of these work. We’ll see below why. As I mentioned above, the values stored in an information object are all vtkObjectBase and subclass instances. However, it is relatively easy to store simple types by wrapping them with simple vtkObjectBase subclasses. For example, we can store integers easily as below.
key = keys.MakeKey(keys.IntegerKey, "another key", "some class") key.Set(info, 12) print info
This prints
vtkInformation (0x7fc3f0db0c80) Debug: Off Modified Time: 55 Reference Count: 1 Registered Events: (none) a new key: vtkObject(0x7f8078e87be0) another key: 12
This example may have made it a bit more clear why the methods to set values on information objects are in the key classes. Using the keys’ API to set values enables us to store multiple types without having to make vtkInformation aware of all types. As long as it can wrap a value or a set of values in a subclass of vtkObjectBase, a key can store data of any type. On the other hand, vtkInformation can only provide the API for the key types it is aware of. You can verify this by checking out vtkInformation.h. It has individual set/get methods for each key type it recognizes. Since most of the code that interact with information objects use already defined key types, you will see the information.Set(key, value) signature much more often. If you define your own key type, you will have to use the key.Set(information, value) signature.
Most often, you will access existing keys rather than create new ones. Keys created in C++ usually exist with the scope of a class and are accessed by calling a static member function. Like so:
info = vtk.vtkInformation() info.Set(vtk.vtkStreamingDemandDrivenPipeline.UPDATE_PIECE_NUMBER(), 1) print vtk.vtkStreamingDemandDrivenPipeline.UPDATE_PIECE_NUMBER() print info
This will print the following.
vtkInformationIntegerKey (0x7fe688c8fa50) Reference Count: 1 vtkInformation (0x7fe688e4ff80) Debug: Off Modified Time: 66 Reference Count: 1 Registered Events: (none) UPDATE_PIECE_NUMBER: 1
When writing code in C++, you can use various macros to create keys. For example, vtkStreamingDemandDrivenPipeline.UPDATE_PIECE_NUMBER() is created using the following.
- vtkStreamingDemandDrivenPipeline.h:
static vtkInformationIntegerKey* UPDATE_PIECE_NUMBER();
- vtkStreamingDemandDrivenPipeline.cxx:
vtkInformationKeyMacro(vtkStreamingDemandDrivenPipeline, UPDATE_PIECE_NUMBER, Integer);
vtkInformationVector is a simple vector of vtkInformation objects. Here is a demonstration.
key = keys.MakeKey(keys.IntegerKey, "another key", "some class")
iv = vtk.vtkInformationVector()
i1 = vtk.vtkInformation()
i1.Set(key, 10)
iv.Append(i1)
i2 = vtk.vtkInformation()
i2.Set(key, 20)
iv.Append(i2)
print iv
for i in range(2):
print iv.GetInformationObject(i)
This will print the following.
vtkInformationVector (0x7ff513e40f10)
Debug: Off
Modified Time: 56
Reference Count: 1
Registered Events: (none)
Number of Information Objects: 2
Information Objects:
vtkInformation(0x7ff513d33c10):
Debug: Off
Modified Time: 60
Reference Count: 2
Registered Events: (none)
another key: 10
vtkInformation(0x7ff513e42230):
Debug: Off
Modified Time: 63
Reference Count: 2
Registered Events: (none)
another key: 20
vtkInformation (0x7ff513d33c10)
Debug: Off
Modified Time: 60
Reference Count: 2
Registered Events: (none)
another key: 10
vtkInformation (0x7ff513e42230)
Debug: Off
Modified Time: 63
Reference Count: 2
Registered Events: (none)
another key: 20
Connecting algorithms to create pipelines
Next, let’s check out how algorithms are connected together to form pipelines. Below is a simple pipeline consisting of 3 sources (s0, s1 and s2) and 3 filters (f0, f1 and f2).
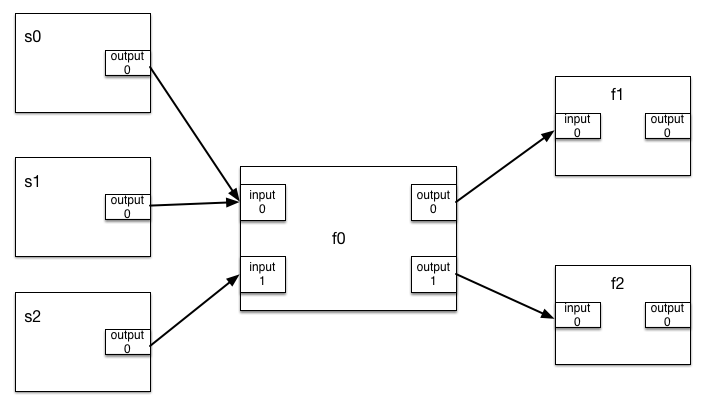
- During execution, data flows in the direction of the arrows,
- s0, s1 and s2 are simple sources with 1 output each,
- f0 is a filter with 2 inputs and 2 outputs. The first input (input 0) is repeatable,
- f1 and f2 are simple filters with 1 input and 1 output.
The code to create this pipeline would look something like this:
s0 = Source() s1 = Source() s2 = Source() f0 = Filter0() f0.AddInputConnection(0, s0.GetOutputPort()) f0.AddInputConnection(0, s1.GetOutputPort()) f0.SetInputConnection(1, s2.GetOutputPort()) f1 = Filter1() f1.SetInputConnection(f0.GetOutputPort(0)) f2 = Filter1() f2.SetInputConnection(f0.GetOutputPort(1))
This is enough detail about the pipeline for now. We’ll cover the pipeline execution order and passes in the next blog. Let’s see what each of these algorithm classes looks like.
Source:
from vtk.util.vtkAlgorithm import VTKPythonAlgorithmBase
class Source(VTKPythonAlgorithmBase):
def __init__(self):
VTKPythonAlgorithmBase.__init__(self,
nInputPorts=0,
nOutputPorts=1, outputType='vtkPolyData')
def RequestData(self, request, inInfo, outInfo):
info = outInfo.GetInformationObject(0)
output = vtk.vtkPolyData.GetData(info)
print info
return 1
When the pipeline is updated with f1.Update() or f2.Update(), the Source instances will print the following 3 times.
vtkInformation (0x7fb87263a8b0) Debug: Off Modified Time: 610 Reference Count: 3 Registered Events: (none) PRODUCER: vtkCompositeDataPipeline(0x7fb872638730) port 0 UPDATE_EXTENT_INITIALIZED: 0 UPDATE_PIECE_NUMBER: 0 UPDATE_NUMBER_OF_PIECES: 1 UPDATE_NUMBER_OF_GHOST_LEVELS: 0 DATA_OBJECT: vtkPolyData(0x7fb8726428c0) CONSUMERS: vtkCompositeDataPipeline(0x7fb8726397d0) port 0
This class is pretty self-explanatory. Note how in RequestData(), there is a direct relationship between the contents of inInfo and the input connections and outInfo and output connections. In the cae of a source, outInfo, which is a vtkInformationVector contains only one vtkInformation object corresponding to the only output. InInfo on the other hand will be empty since this is a source and has no input ports.
Filter1:
class Filter1(VTKPythonAlgorithmBase):
def __init__(self):
VTKPythonAlgorithmBase.__init__(self,
nInputPorts=1, inputType='vtkPolyData',
nOutputPorts=1, outputType='vtkPolyData')
def RequestData(self, request, inInfo, outInfo):
info = inInfo[0].GetInformationObject(0)
input = vtk.vtkPolyData.GetData(info)
info = outInfo.GetInformationObject(0)
output = vtk.vtkPolyData.GetData(info)
return 1
This is also fairly straightforward. A filter with one input and one output. InInfo will contain one vtkInformationVector (first input port) which will contain one vtkInformation (first and the only connection).
Finally, let’s look at Filter0, which is the most complicated algorithm in the example:
class Filter0(VTKPythonAlgorithmBase):
def __init__(self):
VTKPythonAlgorithmBase.__init__(self,
nInputPorts=2, inputType='vtkPolyData',
nOutputPorts=2, outputType='vtkPolyData')
def FillInputPortInformation(self, port, info):
if port == 0:
info.Set(vtk.vtkAlgorithm.INPUT_IS_REPEATABLE(), 1)
return 1
def RequestData(self, request, inInfo, outInfo):
print inInfo
print inInfo[0], inInfo[1]
info = inInfo[0].GetInformationObject(0)
input = vtk.vtkPolyData.GetData(info)
info = outInfo.GetInformationObject(0)
output = vtk.vtkPolyData.GetData(info)
return 1
Overall, this algorithm still looks fairly simple. Its one unusual attribute is how it sets the first port to be repeatable in FillInputPortInformation. This means that this port can accept an arbitrary number of connections, which are established using AddInputConnection(). The most common example of such an algorithm is >vtkAppendFilter. This filter accepts multiple inputs, which it appends together to produce 1 output.
When the pipeline is updated, this will print the following.
((vtkInformationVector)0x11665b830, (vtkInformationVector)0x11665b8f0)
vtkInformationVector (0x7fc52058be30)
Debug: Off
Modified Time: 123
Reference Count: 2
Registered Events: (none)
Number of Information Objects: 2
Information Objects:
vtkInformation(0x7fc52058bef0):
Debug: Off
Modified Time: 666
Reference Count: 2
Registered Events: (none)
CONSUMERS: vtkCompositeDataPipeline(0x7fc52058ae10) port 0
PRODUCER: vtkCompositeDataPipeline(0x7fc520589d70) port 0
UPDATE_EXTENT_INITIALIZED: 0
UPDATE_PIECE_NUMBER: 0
UPDATE_NUMBER_OF_PIECES: 1
UPDATE_NUMBER_OF_GHOST_LEVELS: 0
DATA_OBJECT: vtkPolyData(0x7fc520593f00)
vtkInformation(0x7fc52058d2d0):
Debug: Off
Modified Time: 700
Reference Count: 2
Registered Events: (none)
CONSUMERS: vtkCompositeDataPipeline(0x7fc52058ae10) port 0
PRODUCER: vtkCompositeDataPipeline(0x7fc52058c2b0) port 0
UPDATE_EXTENT_INITIALIZED: 0
UPDATE_PIECE_NUMBER: 0
UPDATE_NUMBER_OF_PIECES: 1
UPDATE_NUMBER_OF_GHOST_LEVELS: 0
DATA_OBJECT: vtkPolyData(0x7fc5205946b0)
vtkInformationVector (0x7fc52058be90)
Debug: Off
Modified Time: 124
Reference Count: 2
Registered Events: (none)
Number of Information Objects: 1
Information Objects:
vtkInformation(0x7fc52058e610):
Debug: Off
Modified Time: 734
Reference Count: 2
Registered Events: (none)
CONSUMERS: vtkCompositeDataPipeline(0x7fc52058ae10) port 1
PRODUCER: vtkCompositeDataPipeline(0x7fc52058d690) port 0
UPDATE_EXTENT_INITIALIZED: 0
UPDATE_PIECE_NUMBER: 0
UPDATE_NUMBER_OF_PIECES: 1
UPDATE_NUMBER_OF_GHOST_LEVELS: 0
DATA_OBJECT: vtkPolyData(0x7fc520594e50)
If you look at the output carefully, you will notice that inInfo contains 2 vtkInformationVector objects, each corresponding to 2 input ports. The first port is repeatable and contains 2 connections. Therefore, the first vtkInformationVector contains 2 vtkInformation objects. The second port accepts only 1 connection and hence the second vtkInformationVector contains only vtkInformation object.
Hopefully, this gives you enough information to get started with writing basic algorithms. In my next blog, I will cover how the pipelines performs multiple passes during execution and how these passes are implement by algorithms.
On to VTK Pipeline Primer: Part 2.
In section “Connecting algorithms to create pipelines” seems to be some inconsistencies related with the first diagram (i.e. there are 3 sources, f0 has two outputs).
Thanks! Fixed.