
Avogadro 2 and Open Chemistry

We have written about the Open Chemistry project in a previous Source article [1], and MoleQueue [2] in a more recent article. Now we will focus on Avogadro 2, and the Avogadro libraries being developed to support the Open Chemistry [3] project. The project recently made its first release [4], tagging version 0.5.0 of all projects on April 11, 2013. Avogadro 2 is a rewrite of the Avogadro codebase, with a focus on scaling to larger problems in chemistry, molecular modeling, materials science, and bioinformatics.
The Avogadro paper describes Avogadro 1.x [5], with a particular focus on the work leading up to and including the 1.0 releases. Another, more recent article describing linking NWChem and Avogadro with the syntax and semantics of the Chemical Markup Language [6] describes collaborative work on an end-to-end solution in open computational chemistry in collaboration with the developers of NWChem [7] and FoX [8]. The diagram below shows the three core Open Chemistry projects, along with the framework development. This article will focus on Avogadro 2 and the libraries that power it.
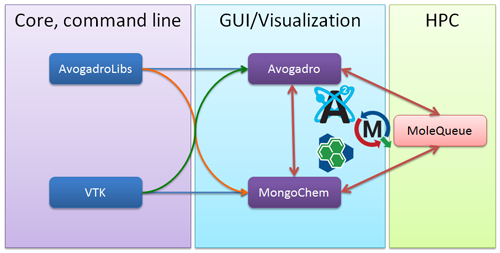
A Brief History of Avogadro
The Avogadro project was founded in 2006, with development really ramping up in 2007 bolstered by a strong collaboration with KDE on the Kalzium [9] project and a Google Summer of Code project to bring a molecular editor to Kalzium. The Avogadro 1.0 release was made in 2009, and a new beta series with many changes (1.1.0) in 2012. Kitware received SBIR funding in 2011 to develop a molecular workbench, with part of the funding allocated to rewriting Avogadro so that it was well positioned to tackle major research problems over the coming years, along with a HPC integration application (MoleQueue), and a cheminformatics application (MongoChem). It remains an open, community project with most of the current development happening at Kitware. We would like to form stronger ties with the wider community, and have worked hard to make a simple, extensible API that others can take and use in their own area of research, teaching, development, etc.
Why Rewrite Avogadro?
One obvious question is why we decided to rewrite Avogadro, rather than incrementally update and improve it. It is always more difficult than anticipated to rewrite, and this project has been no exception. As we developed Avogadro over the years, we learned a great deal and also faced many new problems as the project grew. One of the major issues was that many of the data structures in Avogadro were written with quantum mechanics calculations in mind, which should come as no surprise as the application was initially developed to facilitate GAMESS calculations (predominantly ab-initio methods on small molecules in vacuum).
From those beginnings we generalized the interface in many ways, but were hitting scaling issues and having problems using Avogadro with larger datasets. We also found that some of the interface decisions were not ideal, and as a group we wanted to tackle a larger set of application areas than Avogadro initially set out to address. With that in mind, we have written a new set of core classes, and recently obtained permission from almost all contributors to relicense the code in Avogadro from GPLv2+ to BSD. The code still needs porting, but any issues over licensing have now been cleared up, and we will work on porting all major features over to the new codebase while ensuring testing, validation, and scalability remain a core focus. All of the new code is licensed under the three-clause BSD license, and is not only intended to power the Avogadro 2 application but also provide reference implementations that can be reviewed, tested, and reused in other applications and codes.
Modular Design
One of the major complaints we would get from potential users of Avogadro was that it only had one library, and it contained all of the reusable API. Virtually all classes were derived from, or heavily used, Qt classes; even if you just wanted to reuse a few widgets there was a hard dependency on OpenGL and other components used by the rendering code. When developing the Avogadro 2 libraries, we reexamined the assumptions we made back then and added libraries with minimal dependencies, to allow for core components to be reused without any dependencies. The AvogadroCore library only depends on STL C++11 (with fallbacks to Boost where the compiler doesn’t support C++11). The AvogadroIO library adds a dependency on HDF5, with the AvogadroRendering library using OpenGL and GLEW, and the Qt dependency is contained in the AvogadroQtGui (widgets, model-view, etc) and AvogadroQtOpenGL (QGLWidget integration). This allows many core components to be reused on the command line with minimal dependencies, and opens the door to integration with other GUI toolkits if you would like to reuse the rendering code.
The modular design allows for various components to be reused in a far wider variety of places than was possible before, such as using the file IO classes in command line applications to perform batch operations, or making use of the rendering components and file IO in client-server applications. There is also a lot to be said for a division of concerns within the library, where the rendering code is written to be largely concerned with rendering without directly handling the molecular data, and the scene created has only some degree of integration with the underlying data necessary to facilitate interaction and testing.
Software Process
It should come as no surprise that we have employed an adapted Kitware software process in the development of Avogadro 2, and the wider set of Open Chemistry projects. This involves the use of Git for distributed version control, Gerrit for online code review, CMake/CTest/CDash for cross-platform building and testing, and CDash@Home to test proposed changes. We also use a few things that other projects don’t make use of, such as Google’s testing framework for unit tests, the Qt Testing project from ParaView for regression tests, and image-based regression tests adapted from the VTK project.
Testing
Testing is important, and ideally tests should be written at the same time (or even before) the code. When developing Avogadro 2 we have worked hard to ensure that code can be tested, and results verified. We have reused several components developed in other projects, such as the Google Testing library, image differencing developed for VTK’s testing infrastructure [10], and QtTesting developed to record and replay Qt events in ParaView. This has allowed for a much more thorough set of tests, from unit tests validating functionality in classes through to regression tests verifying drawing operations function as expected in a running instance of the application.
Separate Libraries and Application
Avogadro 1 was written as a library and an application, but because they shared the same repository and build system, issues could slip by that would not work for an Avogadro-based application. When writing Avogadro 2, it was decided to make the application a dependent application, just like any other. This allows us to ensure that everything the application uses has been correctly exposed for external users, and to offer the Avogadro 2 application as an example of how one could use the libraries to develop a full-fledged application of their own. The use of CMake’s external project support, and a superbuild that takes care of coordinating the configuration, build, and installation of all related projects makes it easy for developers to get up-and-running while maintaining the level of separation desired.
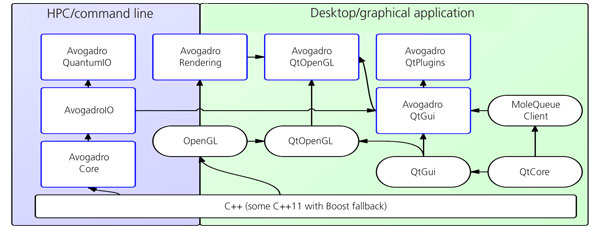
Scalable Data Structures
When considering the design of the core data structures in Avogadro we looked at the need for some data structures in the core that had no Qt dependency, and also at what data structures really needed to be QObject derived in the Qt dependent libraries. QObject derived classes carry quite a bit of overhead, and it was clear from our previous experiences that it was only really the Molecule class that needed to support concepts such as signals and slots. The atoms, bonds, basis sets and other components in the molecule could use lighter weight objects in their representation.
One major issue we wanted to get away from was heavy objects. We could have hundreds of thousands of objects containing optional parameters that must always be allocated; and by adopting a proxy flyweight pattern for most small objects, we could move to a much more efficient core data structure, with simple objects that still feel familiar when accessing components such as atoms and bonds. We are continuing to work on improved data structures, with an emphasis on maintaining flexibility and scalability without placing undue burden on the users of these data structures. It was also important to create classes that could easily and efficiently be serialized/deserialized.
Updated and Improved Rendering
We received a lot of positive feedback from the Avogadro community that the abstraction of rendering code was very useful, with plugins able to implement rendering code that could simply render a blue sphere at position x, y, z with a radius of r. The major problem with the approach we took was one of scalability; every frame we rendered used this API and drew each element one-by-one, which allowed the same rendering code to use OpenGL for interactive rendering and POV-Ray for ray-traced images. However, this approach also created a large bottleneck when attempting to render larger molecules. In Avogadro 2, we made use of a simple, specialized scene graph, which enabled us to maintain a simple API where developers of representations can simply specify sphere, cylinder, and triangle parameters without worrying about the underlying rendering code. It also allows the rendering code to store the scene, and greatly reduces the need to go back to the code that creates the representation. This easily lends itself to batching the rendering of spheres, and making use of efficient vertex buffer objects to store and render geometry.
 Going beyond simple glyphing techniques for spheres and cylinders used previously, we have also implemented billboarded impostors using GLSL-based rendering code to perform simple calculations on the graphics card to determine sphere positions in the fragment shader and lighting calculations. This allows for a sphere to be represented using just two triangles, while still producing results that look more accurate than the typical explicit triangle geometry used in most glyphed representations. We hope to extend this approach in the future to other geometries, such as cylinders and cones, but the largest benefits are seen in spheres when considering typical molecule representations.
Going beyond simple glyphing techniques for spheres and cylinders used previously, we have also implemented billboarded impostors using GLSL-based rendering code to perform simple calculations on the graphics card to determine sphere positions in the fragment shader and lighting calculations. This allows for a sphere to be represented using just two triangles, while still producing results that look more accurate than the typical explicit triangle geometry used in most glyphed representations. We hope to extend this approach in the future to other geometries, such as cylinders and cones, but the largest benefits are seen in spheres when considering typical molecule representations.
Local Socket Communication
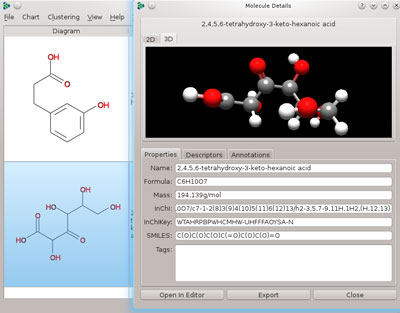
The use of a JSON-RPC 2.0 based communication protocol facilitates loosely-coupled coordination of work between the three Open Chemistry projects, and provides simple entry points for other applications and scripted workflows to make use of Avogadro 2. The server was initially developed in MoleQueue, and has now been reused in Avogadro 2 and MongoChem. Named local sockets provide services that can be registered and used from the other applications; some simple functionality already exposed, in addition to the MoleQueue integration, is the opening of a molecule in Avogadro 2 from MoleQueue and MongoChem, and finding similar molecules in the MongoChem database from Avogadro 2. MongoChem also reuses the 3D rendering and file IO from Avogadro in its dialogs, as you can see in the figure below.
Python-based Input Generators
We thought very carefully about how we could make input generators easier to add, modify, and integrate into Avogadro. Recent work has ported our input generators from Qt/C++ to Python, using the Python interpreter in a separate process, and using multiple passes to get the name in the interface, supported options and syntax highlighting rules, and the generated input. This has a number of advantages over the previous approach, including the use of a separate process to remove most licensing issues, separation of concerns, input generators that cannot crash the main application process, and ease of updating a simple Python script. This work was described in a Kitware blog post [12].
 The framework is largely language agnostic, although we have not exposed the ability to use other languages. As the framework relies on the QProcess class to manage the execution of a process, any language could be used for the input generators that are able to understand JSON and have text processing capabilities. A simple generator can offer no options and generate a fixed output, even taking advantage of text replacement features in Avogadro to insert the molecular geometry into the files. More complex input generators can of course take a large array of options, make use of Python modules, define rules for syntax highlighting, or even execute external processes themselves before producing output. As everything takes place in a separate process, this can all be done serially without any concern about locking the interface.
The framework is largely language agnostic, although we have not exposed the ability to use other languages. As the framework relies on the QProcess class to manage the execution of a process, any language could be used for the input generators that are able to understand JSON and have text processing capabilities. A simple generator can offer no options and generate a fixed output, even taking advantage of text replacement features in Avogadro to insert the molecular geometry into the files. More complex input generators can of course take a large array of options, make use of Python modules, define rules for syntax highlighting, or even execute external processes themselves before producing output. As everything takes place in a separate process, this can all be done serially without any concern about locking the interface.
Integration with Computational Chemistry Codes
The new input generator framework allows users to easily run simulations using the generated input files. By staging and managing computational jobs through MoleQueue, local and remote resources can be used to perform calculations on molecules in Avogadro. This allows users to, for example, draw a molecule, choose a simulation code and parameters, perform the calculation on either the local machine or a remote HPC cluster, then load and visualize the results when the job finishes.
Chemical File Format Framework
Dealing with chemical file formats can be difficult, and we have spent some time developing a flexible and extensible framework for file formats. We make use of a singleton class to manage registration and querying of available file formats, and a simple API to open and save files to different formats. This has been used for several core file formats such as the Chemical Markup Language, Chemical JSON, XYZ, MDL,and several quantum code output formats. We had several requirements up front to be able to seamlessly deal with files on disk, from over the network and from strings, and the goal of supporting composite file formats where data may not reside in the same file.
Quantum Calculation Output
The work that started in Avogadro in the surfaces plugin was later separated into a small library called OpenQube. When we started developing Avogadro 2, it became clear that it would be far easier to fold this functionality into the Avogadro libraries rather than to maintain it in a separate library so that it could effectively reuse many of the data structures developed for Avogadro. While moving it into Avogadro, it was also advantageous to remove the dependencies of the code on Qt and refactor the core classes so that there were data containers and algorithms that act on the data and produce output.
Not only does this make it possible to reuse the quantum data structures in a larger number of places, it opens up the possibility of using different parallelisation strategies for calculating the electronic structure properties. The original code was very tightly coupled using QtConcurrent, which may not always be the ideal choice depending upon application area and hardware/software environment available. This makes it far simpler to explore and implement alternative calculation strategies, including the use of GPGPU computing, OpenMP, and other parallelization technologies without forcing these dependencies.
Open Babel Integration
Open Babel provided a great deal of functionality in Avogadro, and we didn’t want to abandon that in Avogadro 2. We also wanted to move to a more liberal BSD license, and get away from problems associated with the Open Babel design when used in a multithreaded application. We realized that a large amount of the functionality we were most interested in was translating from one file type to another, along with utility functionality such as 3D coordinate generation, simple geometry optimization, and the perception of bonding for organic molecules. This led to the development of an Open Babel extension that manages interaction with the command line obabel executable, which is able to take care of moving data in and out of the code. Not only did this allow us to make use of Open Babel in a separate process, it also simplified what our library needed to link to – allowing us to search for the executable at runtime rather than compile time. This makes it much easier to upgrade Open Babel independently of the application code when desired.
Client-Server Communication
ProtoCall is an asynchronous remote procedure call (RPC) framework that supports RPC using the Google Protocol Buffers library (protobuf). It is being developed to support client-server communication within Avogadro. However, it is a generic framework that can provide support for RPC in C++ for any application. Within Avogadro, ProtoCall is being used to enable the application to run in client-server mode to support computationally-intensive tasks that can be off-loaded onto a server, with the result being retrieved and visualized locally.
 Services in ProtoCall are defined using the protobuf definition language in a .proto file, and a protobuf plugin is used to generate client and server stubs, see the figure above. The client code makes method calls on local classes and the framework takes care of marshalling requests and network communication. On the server-side, the implementer simply provides the service implementation by subclassing the server stub and registering it with the framework. The main idea is that ProtoCall hides most of the complexity of RPC from the user, making it look as simple as a local method call to consumers of the services provided.
Services in ProtoCall are defined using the protobuf definition language in a .proto file, and a protobuf plugin is used to generate client and server stubs, see the figure above. The client code makes method calls on local classes and the framework takes care of marshalling requests and network communication. On the server-side, the implementer simply provides the service implementation by subclassing the server stub and registering it with the framework. The main idea is that ProtoCall hides most of the complexity of RPC from the user, making it look as simple as a local method call to consumers of the services provided.
The communication layer uses VTK, so the standard VTK data types are supported within ProtoCall messages. External data types can be supported by providing serialization/deserialization classes used to write and read instances of the data types to the wire. This is the approach we are using within Avogadro to transfer the base Molecule data type between the client and server, for example.
Future Development
As we look forward to the next six months of development we will focus on integration of the client-server functionality into Avogadro, providing deeper integration with VTK for advanced visualization and analysis; and making a richer desktop application capable of addressing more complex workflows that need multiple molecules loaded at any one time, and multiple widget types that perform specific editing, visualization and analysis tasks. We would also like to explore exposing some simple distance collaboration using the client-server code, and enriching the experience by exposing animation of molecular dynamics trajectories using accelerated views and methods of creating movies.
We are actively seeking collaborators as we look towards tackling new challenges. Please get in touch if you would like to discuss working with us in this area.
Acknowledgements
The majority of the work described here was funded by Engineering Research Development Center (W912HZ-12-C-0005), along with community contributions.
 Marcus D. Hanwell is a Technical Leader in the scientific computing team at Kitware, where he leads the Open Chemistry effort. He has a background in open source, open science, Physics, and Chemistry. He has worked in open-source for over a decade.
Marcus D. Hanwell is a Technical Leader in the scientific computing team at Kitware, where he leads the Open Chemistry effort. He has a background in open source, open science, Physics, and Chemistry. He has worked in open-source for over a decade.
 David Lonie is an R&D Engineer on the scientific computing team at Kitware. He has been active in the open-source chemistry community since 2009, developing for various projects such as the Avogadro editor and the Open Babel toolkit.
David Lonie is an R&D Engineer on the scientific computing team at Kitware. He has been active in the open-source chemistry community since 2009, developing for various projects such as the Avogadro editor and the Open Babel toolkit.
 Chris Harris is an R&D Engineer at Kitware. His background includes middleware development at IBM, and working on highly-specialized, high performance, mission critical systems.
Chris Harris is an R&D Engineer at Kitware. His background includes middleware development at IBM, and working on highly-specialized, high performance, mission critical systems.
References
[1] http://www.kitware.com/source/home/post/39
[2] http://www.kitware.com/source/home/post/93
[3] http://openchemistry.org
[4] http://www.kitware.com/blog/home/post/469
[5] M. D. Hanwell, D. E. Curtis, D. C. Lonie, et al., Avogadro: An Advanced Semantic Chemical Editor, Visualization, and Analysis Platform, J. Chem. Inf., 4 (17), (2012).
[6] W. A. de Jong, A. M. Walker, M. D. Hanwell, From Data to Analysis: Linking NWChem and Avogadro with the Syntax and Semantics of Chemical Markup Language, J. Chem. Inf., 5 (25), (2013).
[7] http://www.nwchem-sw.org/
[8] http://www1.gly.bris.ac.uk/~walker/FoX/
[9] http://edu.kde.org/kalzium/
[10] http://www.kitware.com/blog/home/post/484
I really enjoyed Avogadro 1.2, however, it suddenly stopped working in windows 10. Avogadro 2 doesn’t draw the same and is not as intuitive in the drawing phase. The optimization steps are no longer drawn in process either. If anyone could suggest anything, it would be greatly appreciated.