
CMake ExternalData: Using Large Files with Distributed Version Control

The benefits of distributed version control systems, such as Git, often stem from complete, local storage of a repository’s history; however, such local storage is not without disadvantages. One problem is the addition of large files into a repository. Even if large files are removed from HEAD, their presence in the history increases storage requirements and network transmission time for clones. It is challenging to keep distributed source repositories lightweight.
Yet, large data files cannot be avoided altogether. A common source of large files are testing data. Many projects at Kitware use binary images for testing data that are large relative to source code files.
Previous Work
Several existing approaches attempt to address this problem. One common approach is using a separate Git repository to store testing data, e.g. VTKData for VTK. The separate repository requires extra work for users to checkout and developers to maintain. Furthermore, the data repository still grows large over time. Some projects even maintain multiple separate repositories to store “normal” data and “large” data. Finally, each version of the source code repository must maintain an unambiguous reference to a corresponding version of the data repository or the history of that correspondence is lost. Such correspondence can be maintained, at the cost of workflow complexity, using a Git submodule; e.g. the ITK ITK Testing/Data submodule used prior to the solution covered in this article.
A few third-party Git extensions have been created to address this problem, such as git-annex, git-media, and git-fat. These do not store large files directly in the local repository history, but instead store hash-based references to them. They fetch the actual files on demand from remote repositories and tell Git how to check them out into the local work tree. These are all good tools and their approach is similar to that covered in this article. However, their implementations require additional dependencies like Haskell, Ruby, or Python, and their interfaces add extra Git commands to developer and user workflows.
The CMake Solution
A CMake-based solution to the large-data Git repository problem was developed during the ITK version 4 Git migration. The solution is ideal for projects using CMake as their build system. It is encapsulated in an ExternalData CMake module, downloads large data on an as-needed basis, retains version information, and allows distributed storage.
The design of the ExternalData solution follows that of distributed version control systems using hash-based file indentifiers and object stores, but it also takes advantage of the presence of a dependency-based build system. The figure below illustrates the approach. Source trees contain lighweight “content links” referencing data in remote storage by hashes of their content. The ExternalData module produces build rules to download the data to local stores and reference them from build trees by symbolic links (copies on Windows).
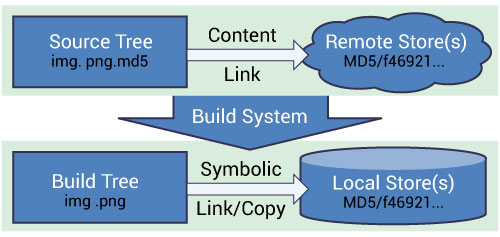
A content link is a small, plain text file containing a hash of the real data. Its name is the same as its data file, with an additional extension identifying the hash algorithm e.g. img.png.md5. Content links always take the same (small) amount of space in the source tree regardless of the real data size. The CMakeLists.txt CMake configuration files refer to data using a DATA{} syntax inside calls to the ExternalData module API. For example, DATA{img.png} tells the ExternalData module to make img.png available in the build tree even if only a img.png.md5 content link appears in the source tree.
The ExternalData module implements a flexible system to prevent duplication of content fetching and storage. Objects are retrieved from a list of (possibly redundant) local and remote locations specified in the ExternalData CMake configuration as a list of “URL templates”. The only requirement of remote storage systems is the ability to fetch from a URL that locates content through specification of the hash algorithm and hash value. Local or networked file systems, an Apache FTP server or a Midas server [MIDAS], for example, all have this capability. Each URL template has %(algo) and %(hash) placeholders for ExternalData to replace with values from a content link.
A persistent local object store can cache downloaded content to share among build trees by setting the ExternalData_OBJECT_STORES CMake build configuration variable. This is helpful to de-duplicate content for multiple build trees. It also resolves an important pragmatic concern in a regression testing context; when many machines simultaneously start a nightly dashboard build, they can use their local object store instead of overloading the data servers and flooding network traffic.
Retrieval is integrated with a dependency-based build system, so resources are fetched only when needed. For example, if the system is used to retrieve testing data and BUILD_TESTING is OFF, the data are not retrieved unnecessarily. When the source tree is updated and a content link changes, the build system fetches the new data as needed.
Since all references leaving the source tree go through hashes, they do not depend on any external state. Remote and local object stores can be relocated without invalidating content links in older versions of the source code. Content links within a source tree can be relocated or renamed without modifying the object stores. Duplicate content links can exist in a source tree, but download will only occur once. Multiple versions of data with the same source tree file name in a project’s history are uniquely identified in the object stores.
Hash-based systems allow the use of untrusted connections to remote resources because downloaded content is verified after it is retrieved. Configuration of the URL templates list improves robustness by allowing multiple redundant remote storage resources. Storage resources can also change over time on an as-needed basis. If a project’s remote storage moves over time, a build of older source code versions is always possible by adjusting the URL templates configured for the build tree or by manually populating a local object store.
Example Usage
A simple application of the ExternalData module looks like the following:
include(ExternalData)
set(midas “http://midas.kitware.com/MyProject”)
# Add standard remote object stores to user’s
# configuration.
list(APPEND ExternalData_URL_TEMPLATES
“${midas}?algorithm=%(algo)&hash=%(hash)”
“ftp://myproject.org/files/%(algo)/%(hash)”
)
# Add a test referencing data.
ExternalData_Add_Test(MyProjectData
NAME SmoothingTest
COMMAND SmoothingExe DATA{Input/Image.png}
SmoothedImage.png
)
# Add a build target to populate the real data.
ExternalData_Add_Target(MyProjectData)
The ExternalData_Add_Test function is a wrapper around CMake’s add_test command. The source tree is probed for a Input/Image.png.md5 content link containing the data’s MD5 hash. After checking the local object store, a request is made sequentially to each URL in the ExternalData_URL_TEMPLATES list with the data’s hash. Once found, a symlink is created in the build tree. The DATA{Input/Image.png} path will expand to the build tree path in the test command line. Data are retrieved when the MyProjectData target is built.
Current Applications
The ExternalData system has experienced rigorous testing in its application in ITK since its initial implementation in early 2011. All of ITK’s testing data are retrieved with the ExternalData system. ITK uses Git hooks to transparently upload new testing data to a publically-accessible server when a patch is pushed to ITK’s code review system. Redundant remote storage resources are maintained by a simple pydas script that scans the source tree for content links before every release and uploads them to a Midas server. Release tarballs are created that do not require Git or a network connection by fetching all the data required for the release and placing them in a local object store within the source tarball.
The ExternalData module has also been successfully applied for the ITKExamples project and recently applied in SimpleITK [SIMPLEITK] and 3D Slicer The ExternalData module is available within CMake with the 2.8.11 release. For details on the application of the ExternalData system, see the documentation in the comments at the top of the ExternalData.cmake file and how it is utilized in existing projects.
In conclusion, the ExternalData module is a good option for projects that already use CMake to dedup storage outside of source and build trees without the need for large data repositories.
 Matthew McCormick is a medical imaging researcher working at Kitware, Inc. His research interests include medical image registration and ultrasound imaging. Matt is an active member of scientific open source software efforts such as the InsightToolkit, TubeTK, and scientific Python communities.
Matthew McCormick is a medical imaging researcher working at Kitware, Inc. His research interests include medical image registration and ultrasound imaging. Matt is an active member of scientific open source software efforts such as the InsightToolkit, TubeTK, and scientific Python communities.
 Brad King is a technical developer in Kitware’s Clifton Park, NY office. He led Kitware’s transition to distributed version control, converted many of our project histories to Git, and conducted training sessions.
Brad King is a technical developer in Kitware’s Clifton Park, NY office. He led Kitware’s transition to distributed version control, converted many of our project histories to Git, and conducted training sessions.
 Bill Hoffman is currently Vice President and CTO for Kitware, Inc. He is a founder of Kitware, a lead architect of the CMake cross-platform build system and is involved in the development of the Quality Software Process and CDash, the software testing server.
Bill Hoffman is currently Vice President and CTO for Kitware, Inc. He is a founder of Kitware, a lead architect of the CMake cross-platform build system and is involved in the development of the Quality Software Process and CDash, the software testing server.