Divide and Conquer

How Modularization Enables Organized Software Growth
The Insight Toolkit (ITK) was modularized recently as part of the work done for the upcoming release of ITKv4. Here we describe the process we followed in order to identify and execute modularization of the toolkit. We hope that this account may give insight to other software development teams on how to prepare for and undertake a modularization effort, particularly by highlighting the things that work well and the mistakes that could be avoided.
What is Modularization?
Modularization is the process of partitioning the code base of a software package into a set of smaller, well-defined packages, the modules. Some of the resulting modules will have dependencies on others. The minimization of dependencies between modules is a measure of success in a modularization effort. Homogeneity of size, making all modules contain about the same amounts of code, is a desirable feature, but not a requirement. In practice, it turns out that it is common to find that modules have a power-log-like distribution of size; that is, a few very large modules, and a multiplicity of medium and small size ones. Given that ITK is an object-oriented, C++ library, the quantum unit of the modularization is the “class” typically implemented as a pair of source code files (.h and .cxx, or .txx). For the purpose of the follow-up discussion here, we will refer to modularization as the effort of of partitioning the files of a software package into modules.
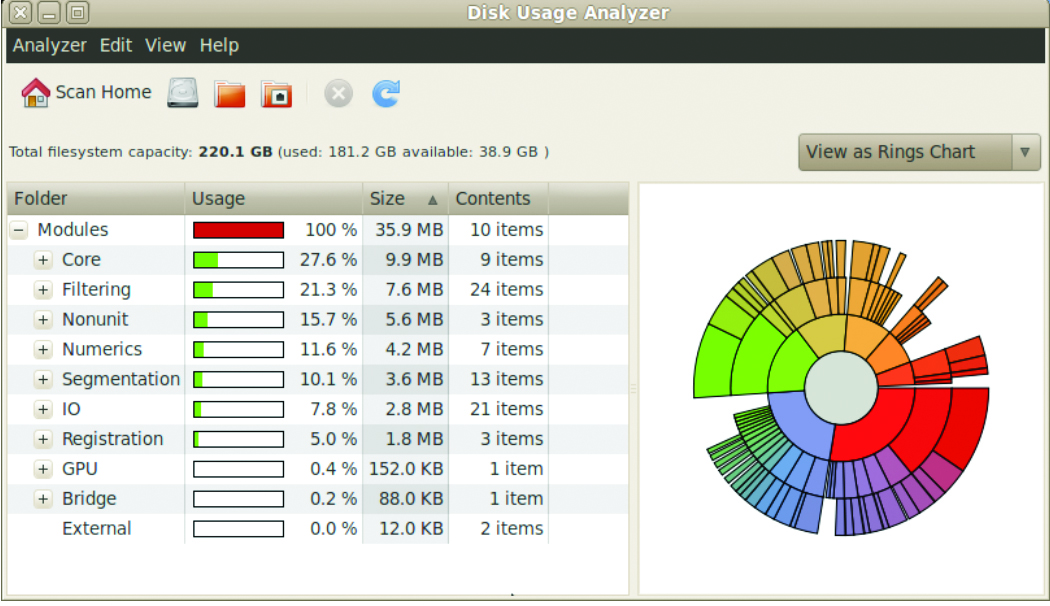
Figure 1. Relative size distribution of group modules excluding third party libraries
Why Modularize?
The motivation for modularizing the Insight Toolkit came from observing the continued growth of the code base, both in terms of lines of code and in terms of scope and type of algorithms and classes. For the past ten years, the toolkit has been growing at an average of about 180,000 lines of code (loc) per year (that is ~15,000 loc/month, or ~500 loc/day).
The difficulty of code maintenance increases more than linearly with the number of lines of code, given that the interactions between different parts of the code increase exponentially. The very action of adding lines of code to the code base introduces the challenges of ensuring that the new code is consistent with the existing one, and that it doesn’t bring in any modifications that break existing functionalities. Over time, it becomes prohibitively expensive to support the quality control process required to continuously add code to a single pool package. The dreadful consequence is that quality is sacrificed as for every new line of code, new defects are introduced. Modularization mitigates this problem by restoring the independence between subsections of the code, and essentially converting a large software package into many medium size ones.
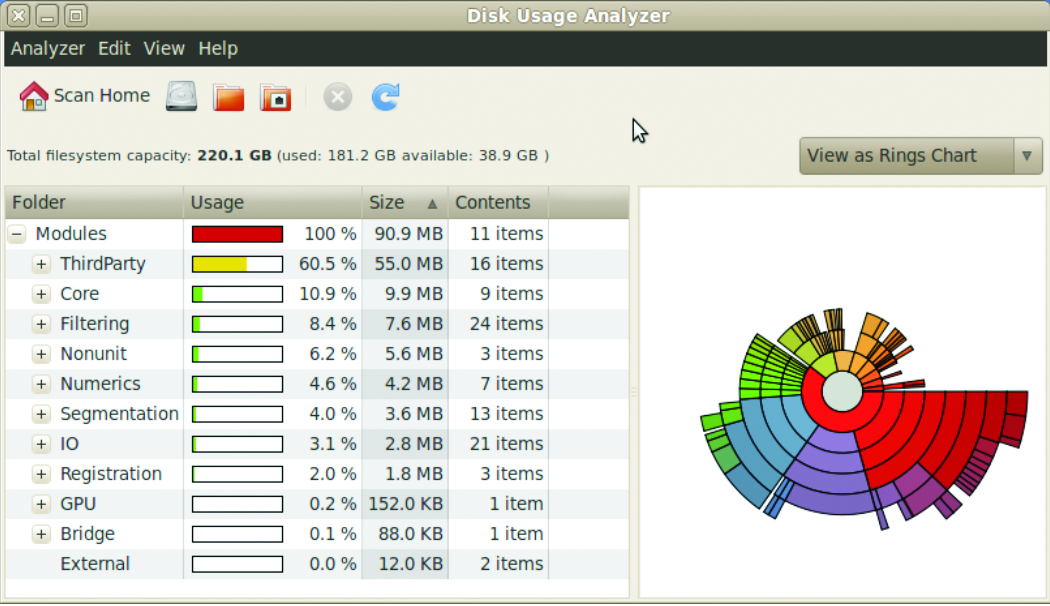
Figure 2. Relative size distribution of group modules including the entire toolkit
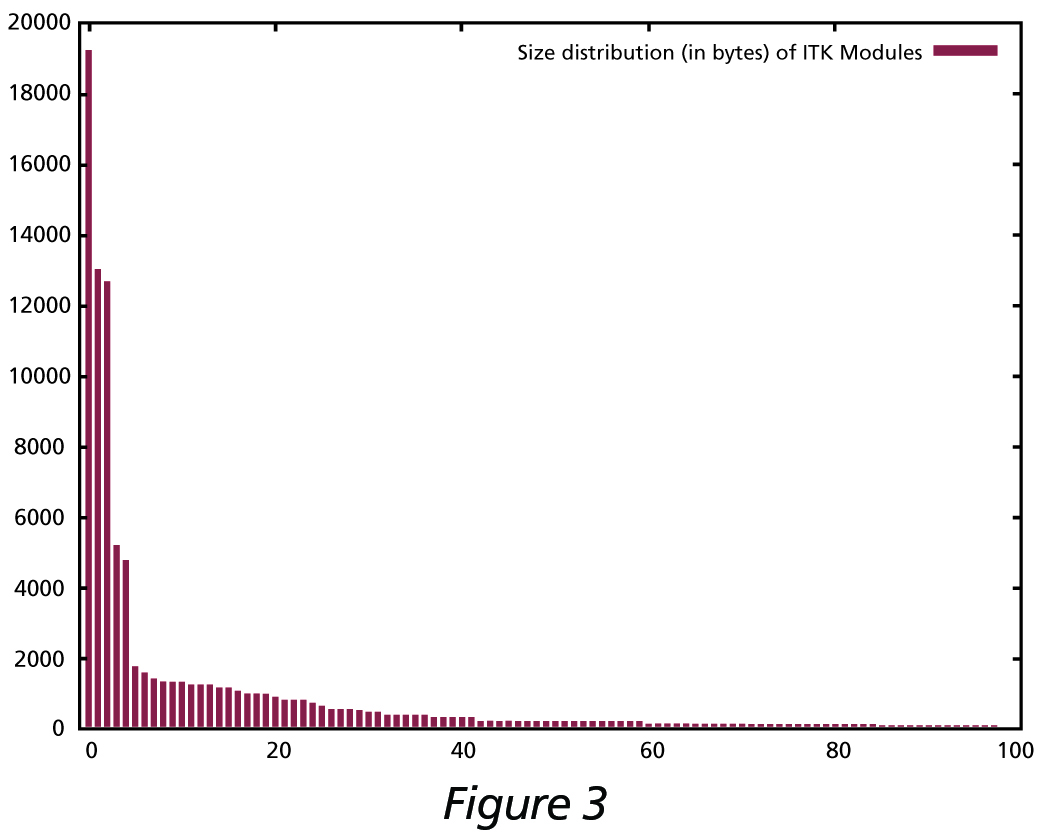
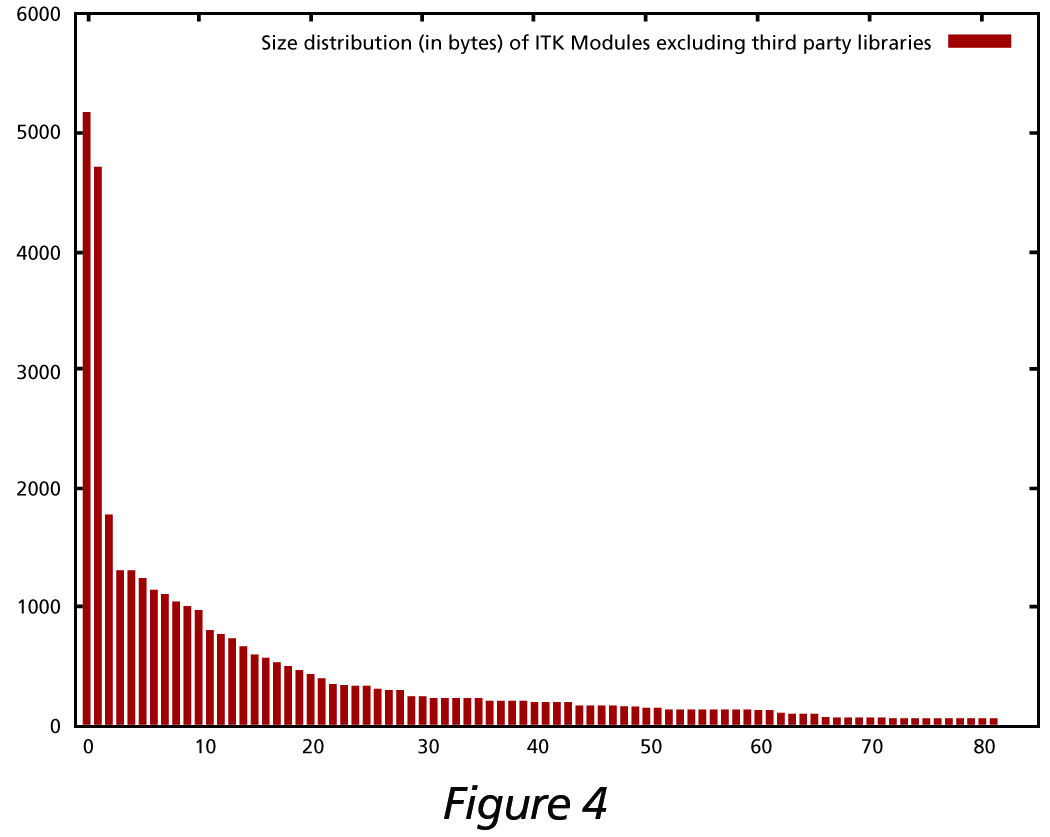
The next figures illustrate this point. Figure 3 shows the size distribution of ITK modules. The three largest modules are actually third-party libraries (VXL, GDCM, HDF5), while the ITKCommon module is the largest one. Figure 4 shows the size distribution of ITK modules excluding the third party libraries. The largest five are Core-Common, Nonunit-Review, Numerics-Statistics, Registration-Common, and Core-Transforms.
How to Modularize?
The modularization process aims to group together pieces of code (files) that have interrelated functionalities in the same module, while simultaneously minimizing the level of crosstalk between separate modules. In an ideal world, if we had information about all the dependencies and interactions between source code files, we could perform a graph-cut partition of the toolkit. Unfortunately, the automatic identification of dependencies is not a trivial problem. In our initial take, we attempted to mine the information that Doxygen gathers when it is building the class collaboration diagrams. We then explored the option of mining the database that SourceNavigator builds when it analyzes a software package, and also the use of the database created by ctags. After several weeks of effort on these fronts, we realized that such a problem as worth a Ph.D. dissertation, and that we needed a more pragmatic approach in order to match the schedule of our project. Therefore, we resorted to the manual classification of files into modules, supported by continued testing to identify whether any dependencies have been missed.
How to Maintain a Modularized Package?
Here, we are against the second law of thermodynamics. It is one thing is to organize a room, and another to keep that room organized afterwards. We don’t quite have a magic solution for this second part, but do have mistakes to share and ominous signs to watch for.
Mistake #1: When a new dependency is discovered (or introduced) between a file in module A and a file in module B, the quickest solution is to make the entire module A depend on the entire module B. Paradoxically, because the CMake setup we created makes it so simple to add a dependency between modules, this quick, self-defeating shortcut is an easy one to take. However, this must be avoided at all times. Every inter-module dependency that you add defeats the purpose of the modularization, and brings you back to the situation where maintenance will be too expensive and the quality of the code will degrade.
Mistake #2: As the modules become independent, they also tend to be maintained by a different subset of the development team and start diverging on style, design and practices. This is essentially a forking in the work that must be prevented by introducing automated tools for verification and by requiring code reviews by other members of the team. It is a truism of human nature that we continuously attempt to put our personal touch on what we create; unfortunately, that’s undesirable in large-scale
software projects. Professional software developers must write code that others can take over. They must work every day to make themselves replaceable. It is that mindset that will guide the developer to: (a) generously comment code, (b) adhere to consistent style, (c) fanatically write tests for new code, (d) leave traces connecting to the discussions that led to the current code design. Good software developers write code that can survive once they are gone.
Extreme Modularization
If we apply the modularization rationale to the limit, we reach the corollary that matches one of the oldest rules of a job well done: “Do one thing; do it right!” The modern version of it in object-oriented programming is known as the “Law of Demeter” or the “Principle of least Knowledge.” This leads to the fact that classes should have a minimum of dependencies between them. It is a trade-off with the principle of avoiding duplication of code that leads to create classes that provide services to other ones.
These observations show that modularization is not only a software packaging exercise, but it also has to be accompanied by design decisions and a software process that takes advantage of finer granularity for making it easier to detect defects and remove them from the system.

David Cole is an R&D Engineer in Kitware’s Clifton Park office. David has contributed code to the VTK, CMake, ITK, ParaView, KWWidgets and gccxml open‐source projects and to Kitware’s proprietary products including ActiViz and VolView.

Bill Hoffman is currently Vice President and CTO for Kitware, Inc. He is a founder of Kitware, a lead architect of the CMake cross-platform build system and is involved in the development of the Kitware Quality Software Process and CDash, the software testing server.

Luis Ibáñez is a Technical Leader at Kitware, Inc . He is one of the main developers of the Insight Toolkit (ITK). Luis is a strong supporter of Open Access publishing and the verification of reproducibility in scientific publications.

Brad King is a technical developer in Kitware’s Clifton Park, NY office. He led Kitware’s transition to distributed version control, converted many of our project histories to Git, and conducted training sessions.

Xiaoxiao Liu is an R&D engineer in the medical imaging team at Kitware. She joined the company in September 2010, and has a background in medical image analysis. She has been working on ITKv4 and Lesion Sizing Toolkit.