
Introduction
This web page contains the supplemental material for the AVSS 2015 paper An End-to-End System for Content-Based Video Retrieval using Behavior, Actions, and Appearance with Interactive Query Refinement, presented at the 12th IEEE International Conference on Advanced Videoand Signal based Surveillance (AVSS) [http://avss2015.org]. A version of the paper for personal use only can be viewed here.
Contents, as referenced in the paper:
- Videos of example results
- More details on the analysis of the effects of Interactive Query Refinement (IQR)
- Additional results exploring IQR sensitivity to the exemplar query
- Explanation of descriptor selection for evaluation
- Demonstration of cross-sensor modality (EO vs. IR) retrieval
- Expanded discussion of indexing and retrieval
1. Videos of example results
An exemplar clip of a carrying event is shown in query-clip.wmv. The results after two rounds of IQR, using appearance, articulation and trajectory descriptors on the same archive as the results in the paper, are shown in top10-2rounds-4desc.wmv. The first return (0) is the query clip. Note the variety of different carrying events that are matched, in terms of viewpoint, pose and object being carried.
A video showing a “person moving” query executed and adjudicated through the GUI is in GUI-person-moving.wmv. This shows the returned video clips, and the detected person tracks within the clips that match the query. Near the end, IR video and IR results are shown. These IR person detections were matched from the original query.
2. Analysis of the Effects of Interactive Query Refinement (IQR)
Here we augment the discussion from Section 8 of the paper, concerning how IQR improves results. The top row of Supplementary Figure 1 reproduces the curves from Figure 6 in the paper, which showed how IQR improved the results of an exemplar carrying query.
Recall that this query was chosen because we have full ground-truth for it in the video archive, i.e. all instances are annotated with space-time bounding boxes. This is not true for the other three “ad hoc” IQR experiments (backpack, shovel, vehicle), which were not annotated in the ground-truth. Instead, those results were scored by manual inspection, and the prior was estimated by manually counting instances in the top 100 results of a “person-moving” query. The bottom row shows the same plots, zoomed in on the left side. Items of note:
The threshold parameter for both curves is the “relevancy” of the result estimated by IQR. The curves trace out, left-to-right, the most-to-least relevant results; the GUI presents the most relevant results first. In other words, the left side of the curves represent the results the user sees first. The bottom row of Figure 1 emphasizes that as IQR’s re-ranking operation changes the relevancy of the results, the intial results presented to the user become more accurate in each round.
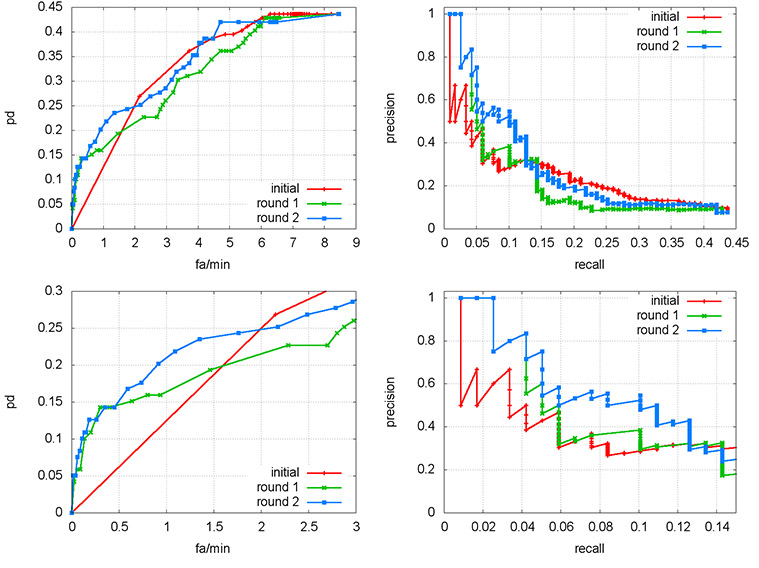
Supplementary Figure 1. Top row: ROC and P/R curves from Figure 6 in the paper; bottom row: left side of the curves to highlight IQR effects on top-ranked curves.
However, note how in the limit of the curves (the right-hand side), all rounds of IQR converge to the same performance. This is because IQR cannot improve the maximal Pd; it can only alter the order in which results are ranked and presented. Once the set of descriptors has been selected by the user (Section 6 of the paper), the probability of detection (Pd) of the overall set of results (whose size may be in the hundreds to low thousands) is fixed. The value of IQR does not lie in improving maximal Pd at an arbitrarily high false alarm rate; the value of IQR is improving analyst efficiency by presenting the most relevant results first.
3. IQR Sensitivity to Exemplar Query
Here we examine the sensitivity of IQR to the initial exemplar query, by analyzing the robustness of query results when different exemplars are chosen. Even with IQR, query results will not be independent of the initial query, but it is desirable that different queries of the same action should yield similar results.
Recall that the exemplar query generates the initial set of descriptors which are used as the initial probe into the descriptor space of the full archive.
Supplementary Figure 2 shows the original carrying exemplar from the paper (#26, top row) as well as three additional exemplars, which were processed identically to give the ROC and P/R curves shown in Supplementary Figure 3. In this figure, the top row shows the curves over the entire return set, while the bottom row zooms in to the left side as in Supplementary Figure 1 above. There are two items of note:
Exemplars #89 and #98 are generally comparable to #26 (although see below), but observe that Exemplar #45 is markedly worse, in that its P/R performance is actually decreased by IQR (Supplementary Figure 3, bottom right). This is probably because the exemplar track was very short, and as shown in Supplementary Figure 2, it only yielded 2 articulation descriptors, while the other exemplars yeielded between 14 and 18.
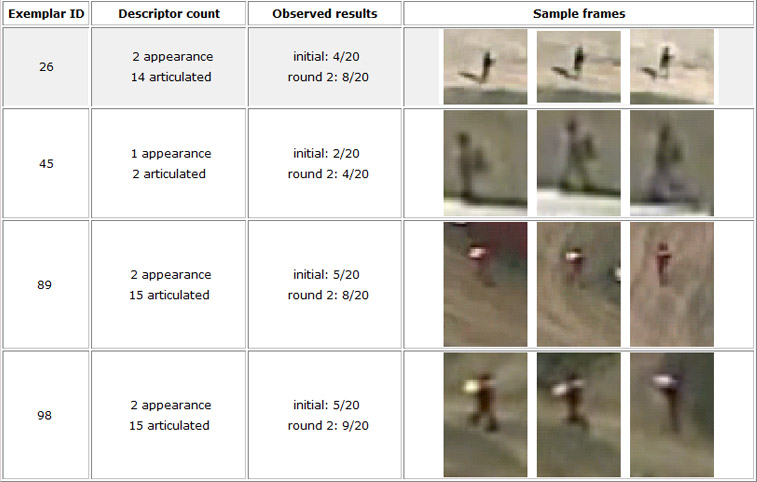
Supplementary Figure 2. Suite of four carrying exemplars; #26 (top row, shaded) was used in the paper. Column two details how many and what type of descriptors the exemplar yielded. Notice that due to its length, #45 only yields two articulated descriptors.
The P/R curve for #89 starts off with zero precision, rather than one. This is because, despite the obvious carrying activity visible in row three of Supplementary Figure 2, the ground-truth for this exemplar track labels the activity as “PersonWalking”, not “PersonCarrying.” This highlights the fact that ground-truthing a dataset as extensive and nuanced as the VIRAT Video Dataset can only approach complete accuracy, but probably never reach it.
The observed results in column 3 of Supplementary Figure 2 roughly track the improvement in Pd in Supplementary Figure 3; from this we can conclude that as long as the exemplar yeilds enough descriptors, the IQR process is reasonably robust to the initial query.
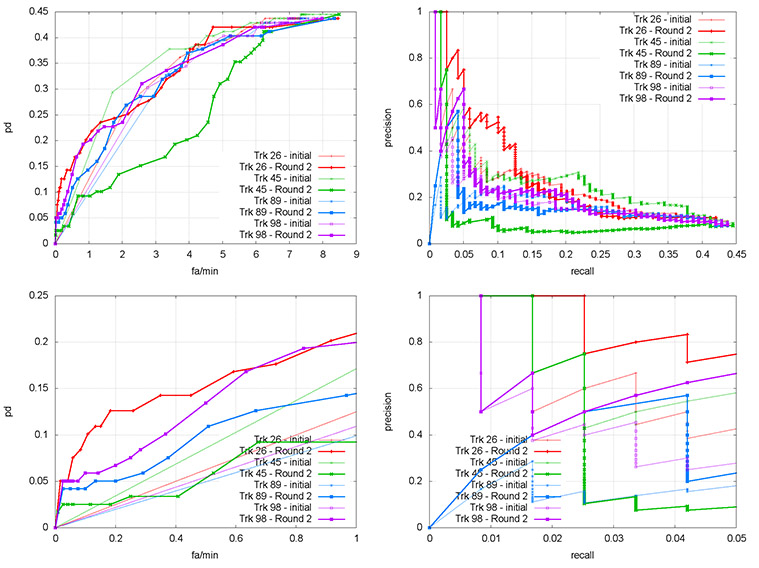
Supplementary Figure 3. IQR results on four ad hoc carrying examples, initial (thin line) and after two rounds of IQR (thick line). Top row is full return set, bottom row is close-up of curve corresponding to results presented first by the GUI. #26 is from the paper.
4. Descriptor selection for evaluation
Section 6 of the paper describes the variety of descriptors designed, implemented, and tested during system development. Not all of these behavior and appearance descriptors were used in the experiments described in the paper. During system development, extensive experiments were conducted on non-public data which was comparable to the VIRAT Video Dataset. These experiments showed that the HOG-based descriptors were more accurate independently, and contributed more to the fused results than the Histogram of Optical Flow (HOF) and Dynamic Bayesian Network (DBN) descriptors. Consequently, the HOF and DBN descriptors were not used in the experiments described in the paper.
5. Cross-modality retrieval
The paper asserts in the introduction that The system processes both RGB and infra-red video; queries in on modality may yeild results in either. Although extensively exercised on non-public data, the public aerial data contains only approximately 400 seconds of IR data out of 7200 seconds; in other words, about 5.5% of the archive is IR. Due to the paucity of IR data and the preponderance of walking in the ground-truth (both EO and IR), the only usable IR exemplar is “person walking”. Supplementary Figure 4 shows the results of an initial query and a single round of IQR. The query clip is result 0; the initial query returns a number of hits (reflecting the amount of walking in the archive); one of the additional hits (#3) is also IR. One round of IQR bring in four more IR results, two of which (#11, #17) are hits, the other two (#14, #19) are false alarms which would receive negative feedback.
6. Indexing
The goal of indexing and retrieval in our system is to provide significantly faster searching through large volumes of video data. Tree based structures can be efficient for low-dimensional data, but scale poorly in in terms of storage and access time for high-dimensional feature spaces like those used in visual descriptors. Uniform space partitioning [2], while highly scalable with large dimensions and number of data points, does not capture the high-dimensional space well, resulting in undetermined upper boundary on the selected set candidates. Locality Sensitive Hashing (LSH) [1] assigns similar data (for a given distance metric) to the same bucket while relying on the probabilistic boundaries on approximate search. Our indexing engine is specifically tuned for high-dimensional descriptors, providing significantly improved performance on our typical problems.

Supplementary Figure 4. Left, initial results on an infra-red (IR) person walking example. The exemplar query is result 0; result 3 is another hit in IR; other results with green IDs are also hits. Right, results after one round of IQR bring in two more IR hits (11 and 17) as well as some IR false alarms (14 and 19.)
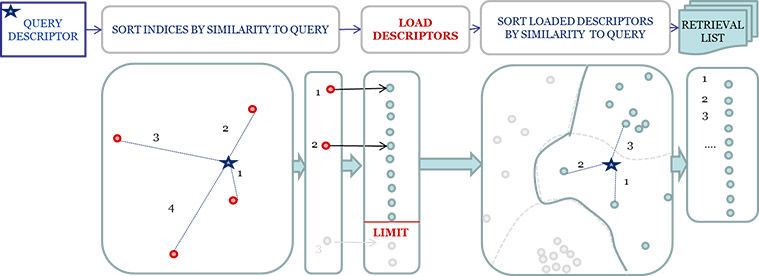
Supplementary Figure 5. The indexing and retrieval method.
Our system uses a data driven indexing approach, as illustrated in Supplementary Figure 5. Prototypes of data clusters in the high dimensional space become search indices. At query time, these indices are matched to the query vector, and nearest neighbors to the best matching indices are retrieved. These nearest neighbors are then sorted by similarity to the query vector to generate the ranked retrieval list. For a fixed retrieval size, this process can be optimized to limit the amount of descriptors that need to be returned from the database and sorted by similarity.
These indices can be created individually for each feature type, enabling indices which are smaller, faster, and more accurate for a given feature type. However, with multiple indices, the resulting lookups for a given feature vector must be merged. Fusing across these disparate feature spaces is still an active research area, as distance scores in different vector spaces are not necessarily directly comparable. Our approach uses score balancing, score merging, and context scaling to address this challenge. Score balancing uses the distribution of scores within an index to convert the distance score into a similarity score between 0 (least similar) and 1 (most similar). For example, one easy way to do this is to normalize using the range of the data. Score merging leverages the similarity score returns to create a ranked list across the multiple indices. This list may have multiple entries for the same item (i.e. entries from multiple indices) which will need to be resolved prior to settling on the final ranked return list. However, multiple entries provides additional evidence for the importance of a particular return. Context scaling leverages the PVO descriptor, which characterizes query events as coming from a person, vehicle, or other (typically a false alarm). It is expected that the most likely PVO value for a query item will be similar to the PVO value for a return item (i.e. vehicle events should be returned for a vehicle event query). This evidence can be used during the final ranking to discard unlikely matches.
7. The DARPA VIRAT evaulation
As part of the DARPA VIRAT program, MITRE Corporation conducted an independent third-party evaluation of the system over a two-week period. The evaluation involved analysts interacting with archives of operational data and assessing how its present and prospective capabilities might influence future analyst workflows; feedback was generally positive.
8. IQR results for Shovel and Vehicle queries
Here we present keyframes from the results of the Shovel and Vehicle IQR experiments from Section 8 of the paper.
Shovel query

Initial (top) and final (bottom) top 10 results for the IQR ‘shovel’ experiment; relevant returns are in green. The visual similarity of the static images highlights the importance of temporally sensitive descriptors.
Vehicle query

Initial (top) and final (bottom) results for the IQR ‘vehicle’ experiment. Results in red were actively stated to be ‘not relevant’.
Author contact information
Anthony Hoogs: anthony.hoogs@kitware.com
A. G. Amitha Perera: amitha.perera@gmail.com
Roderic Collins: roddy.collins@kitware.com
Arslan Basharat: arslan.basharat@kitware.com
Keith Fieldhouse: keith.fieldhouse@kitware.com
Charles Atkins: chuck.atkins@kitware.com
Linus Sherrill: linus.sherrill@kitware.com
Ben Boeckel: ben.boeckel@kitware.com
Russell Blue: rusty.blue@kitware.com
Matthew Woehlke: matthew.woehlke@kitware.com
Christopher Greco: christopher.r.greco@gmail.com
Zhaohui (Harry) Sun: harry.sun@kitware.com
Eran Swears: eran.swears@kitware.com
Naresh Cuntoor: nareshpc@gmail.com
Jason Luck: jason.p.luck@lmco.com
Brendan Drew: brdrew@comcast.net
Danny Hanson: danny.hanson@lmco.com
John Kopaz: john.a.kopaz@lmco.com
Trebor Rude: trebor.a.rude@lmco.com
Dan Keefe: dan.c.keefe@lmco.com
Amit Srivastava: asrivast@bbn.com
Saurabh Khanwalkar: skhanwal@bbn.com
Anoop Kumar: akumar@bbn.com
Chia-Chih Chen: chiachih.chen@gmail.com
J.K. Aggarwal: aggarwaljk@mail.utexas.edu
Larry Davis: lsd@cs.umd.edu
Yaser Yacoob: yaser@umiacs.umd.edu
Arpit Jain: arpitjain1@gmail.com
Dong Liu: dongliu@ee.columbia.edu
Shih-Fu Chang: sfchang@ee.columbia.edu
Bi Song: bi.bsong@gmail.com
Amit K. Roy Chowdhury: amitrc@ece.ucr.edu
Ken Sullivan: sullivan@mayachitra.com
Jelena Tesic: tesic@mayachitra.com
Shivkumar Chandrasekaran: shiv@mayachitra.com
B. S. Manjunath: manj@mayachitra.com
Xiaoyang Wang: wangx16@rpi.edu
Qiang Ji: qji@ecse.rpi.edu
Kishore Reddy: reddykishore@gmail.com
Jingen Liu: jingen.liu@sri.com
Mubarak Shah: shah@eecs.ucf.edu
Yao-Jen Chang: kevin.yjchang@gmail.com
Tsuhan Chen: tsuhan@ece.cornell.edu
References
[1] A. Gionis, P. Indyk, and R. Motwani. Similarity Search in High Dimensions via Hashing. In Proc. 25th International Conf. on Very Large Data Bases, 1999.
[2] G. Wyvill, C. McPheeters, and B. Wyvill. Data structure for soft objects. Visual Computer, 2, August 1986.
Physical Event