How Wikipedians put Researchers to Shame

While searching online for the latest figures of Web Browsers market share,
I came accross this interesting figure in the Wikipedia:
.svg){kind=link}

This is based on data from StatCounter’s report, that can be freely downloaded.
As interesting as this figure is, for driving endless geek discussions, the same Wikipedia page held a Gem of much greater interest!
Under the section “Summary“, with the description:
.svg#Summary){kind=link}
We find indeed the R source code:
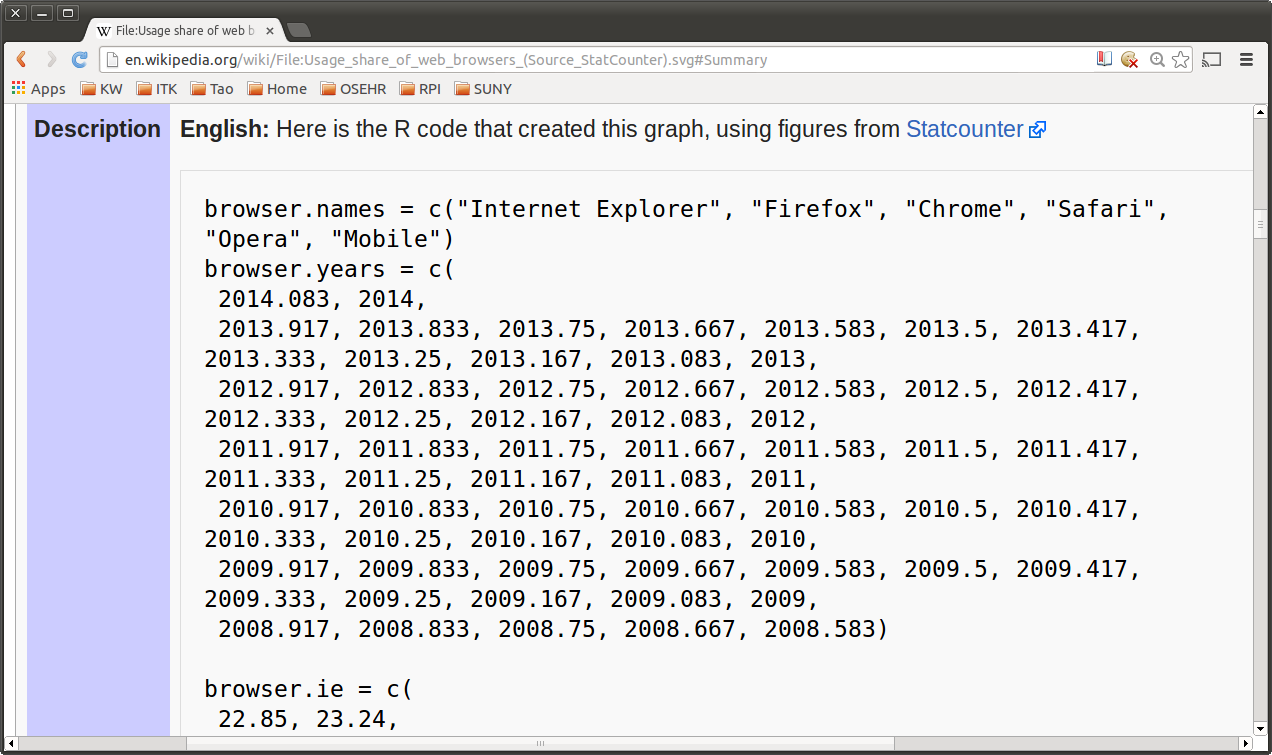
Followed by the instructions on how to run the code in Linux
This is the Hallmark Signature of the true Scientist:
Describe the process of the experiment and provide all the elements needed for an independent observer to replicate the work.
This illustrates how we already have at hand all the tools needed to implement Reproducible Research on a daily basis, and we are mostly confronted with a Cultural shift, on making clear that is no longer acceptable to publish papers that do not include the full set of elements needed to verify its replicability.
Of course, it is not enough, to “take their word for it…”, so, I followed the instructions, copy-pasted the R code, in a file, and ran it in an Ubuntu Linux machine, as Rscript webbrowsers.r and got the following replicated svg file:
“Usage share of web browsers (Source StatCounter).svg”
pasted here:

Tip of the Hat to to the Wikipedia page authors:
Thanks for showing how scientific work ought to be performed and publihsed !

“Nullius in Verba”
“Take Nobody’s word for it”
“It is an expression of the determination of Fellows of the Royal Society
to withstand the domination of authority
and to verify all statements by an appeal to facts determined by experiment.”
Addendum
Stepan Roucka rightly pointed out that in the R example above, the data was
already embedded in the script and therefore, it was not a clean example of
reproducible research. Particularly because the provenance of the data was
not explicit, and it was not clear how the data was put into the script.
This addendum attemps to address Stepan’s point, this time using an
iPython script, and putting all the elements together int this git repository:
https://github.com/luisibanez/browsers-www-monthly
Where the data has been downloaded from StatCounter, using the URL listed here:
https://github.com/luisibanez/browsers-www-monthly/blob/master/data/README.md
and the same URL is used directly in the python script,
taking advantage of pandas availity to download/read files using an URL.
The full script is now:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# Read data from the local disk
# browsers = pd.read_csv('../data/browser-ww-monthly-200812-201402.csv')
# Or download it from StatCounter directly
browsers = pd.read_csv('http://gs.statcounter.com/chart.php?201402=undefined&device=Desktop%20%26%20Mobile%20%26%20Tablet%20%26%20Console&device_hidden=desktop%2Bmobile%2Btablet%2Bconsole&statType_hidden=browser®ion_hidden=ww&granularity=monthly&statType=Browser®ion=Worldwide&fromInt=200812&toInt=201402&fromMonthYear=2008-12&toMonthYear=2014-02&multi-device=true&csv=1')
somebrowsers = browsers[['IE','Firefox','Chrome','Safari','Opera']]
somebrowsers.plot()
The repository also has the corresponding IPython notebook script.
that generates the following figure:
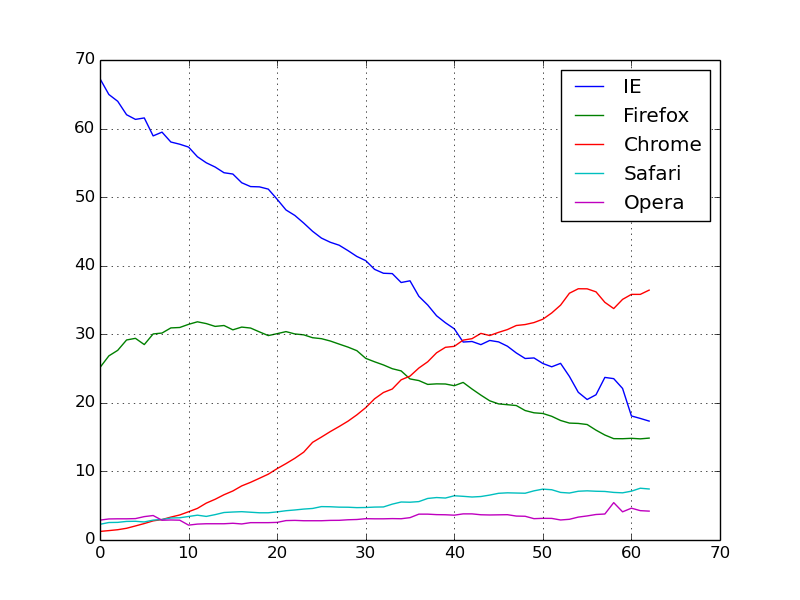
Thanks Stepan for pointing this out.
This does not seem to me like independent verification of the results, because the data are already hardcoded in the R script. It would work if the script pulled the data in csv from statcounter and plotted them…
Štěpán,
Thanks for pointing this out. I agree with you in that a better example of reproducible research should include the direct download from the data source.
I have now included this in an addedum, using IPython and pandas. This time, the data is downloaded directly from the source.
The scripts, and a copy of the data file are now in a public git repository: