
National Day of Civic Hacking – SUNY Albany / Kitware

On June first we celebrated the National Day of Civic Hacking in Albany
![]() by hosting a Random Hack of Kindness event at the State University of New York at Albany.
by hosting a Random Hack of Kindness event at the State University of New York at Albany.
Preparations for the hackathon were detailed in a previous blog post.
As with any good hackathon, the day started with coffee and cookies:

Thanks to Catherine Dumas for the coffee and to Dona Kochis for the cookies!

The Hacking banner (sent by the National Day of Civic Hacking organizers) was hung with honors (and a bit of struggle) using wires from a TI MSP 430 launchpad micro-controller kit.
 Thanks to Tim Fake for contributing the wires to the cause of Civic Hacking. Lack of proper supplies should never stop hackers from meeting their challenges!
Thanks to Tim Fake for contributing the wires to the cause of Civic Hacking. Lack of proper supplies should never stop hackers from meeting their challenges!
* * *
With the opening festivities done, we engaged in the honored unconference practice of discussing, as a group, just what to do during the day. We jointly contributed to an openly shared Google document where we recorded participants, ideas, approaches, and events during the day.
The group decided to engage in a social network mapping exercise using data from We The People. This site was created by White House to receive petitions that are submitted to the President and his staff.
The White House published an API that provides access to data from petitions with more than 150 signatures.
https://petitions.whitehouse.gov/developers
With the following API, a hacker can download petition data in the JSON format.
https://api.whitehouse.gov/v1/petitions.json?limit=3&offset=0
Although it is not clear why in hindsight (sometimes hackathons proceed in mysterious ways), the group began by downloading a SQL data file, containing both the petition data and SQL code for creating a relational database surrounding the data.
https://api.whitehouse.gov/v1/downloads/data.sql.zip
(203.5 MB, last updated 5/1/2013)
First, we loaded the data file into an Amazon Web Services (AWS) cloud instance. This instance was courtesy of an Amazon AWS Educational Grant provided to the University at Albany’s College of Computing and Information (CCI) this spring.

Alex Jurkat coordinated the activity and kept us on track during the day.
 |
 |
CCI Dean Peter Bloniarz visited the hackathon to see what the group was working on and to express his support.

Interpreting the structure of the relational database, what data was available, and how it fit together took a couple hours.
The data turned out to have
- Information about every petition (id, title, body text, created date, number of signatures, number of signatures needed to reach the 10,000 threshold for a White House response, the id of any response).
- Information about “signature instances” which was composed of partially anonymized, self-reported name initials, zip codes, and a petition id. We found that some initials were unreadable (showed up in the database as “xx”), some zip codes were missing, and zip codes data varied from 5 digits to 9 digits to combinations of digits and characters (indicating non-US postal codes).
In general, the group’s effort resulting from the formatting of the data illustrates the point of the Open Data Policy, by dictates that all data published by the Federal government should be contained in Machine Readable formats.
After gaining an understanding of the data, we found
-
1,806 petitions total,
-
nearly 13 million petition signature instances,
-
and 2.7 million distinct initial and zip code combinations.
Armed with this understanding of the data, the group decided to use the graphical interface attached to the Neo4j graph database tool to create a more easily understandable social network of petitions and signature instances.
First, we needed to query the relational database to pull out the data on signature instances and their corresponding petition id and title. Given the structure of the database, that proved difficult.
 Here are Dima Kassab, Seth Chaiken, and Alex Jurkat, working on the query problem.
Here are Dima Kassab, Seth Chaiken, and Alex Jurkat, working on the query problem.
Towards the end of the day, the group isolated the relevant data (nearly 13 million records). In the meantime, Luis Ibanez and Dima Kassab devised a means to import the query data into Neo4j by using curl and Bash scripts to communicate with the REST API of Neo4j. Each petition and each signator (combination of initials and zip code) became a node in the graph database. Each signature instance became a line between a signator and a petition node. The resulting database can be found at http://54.225.78.7:7474/webadmin/.
The group’s first graphical rendering of the Neo4j database with petition, signator, and signature instance information created a pleasing and informative picture.
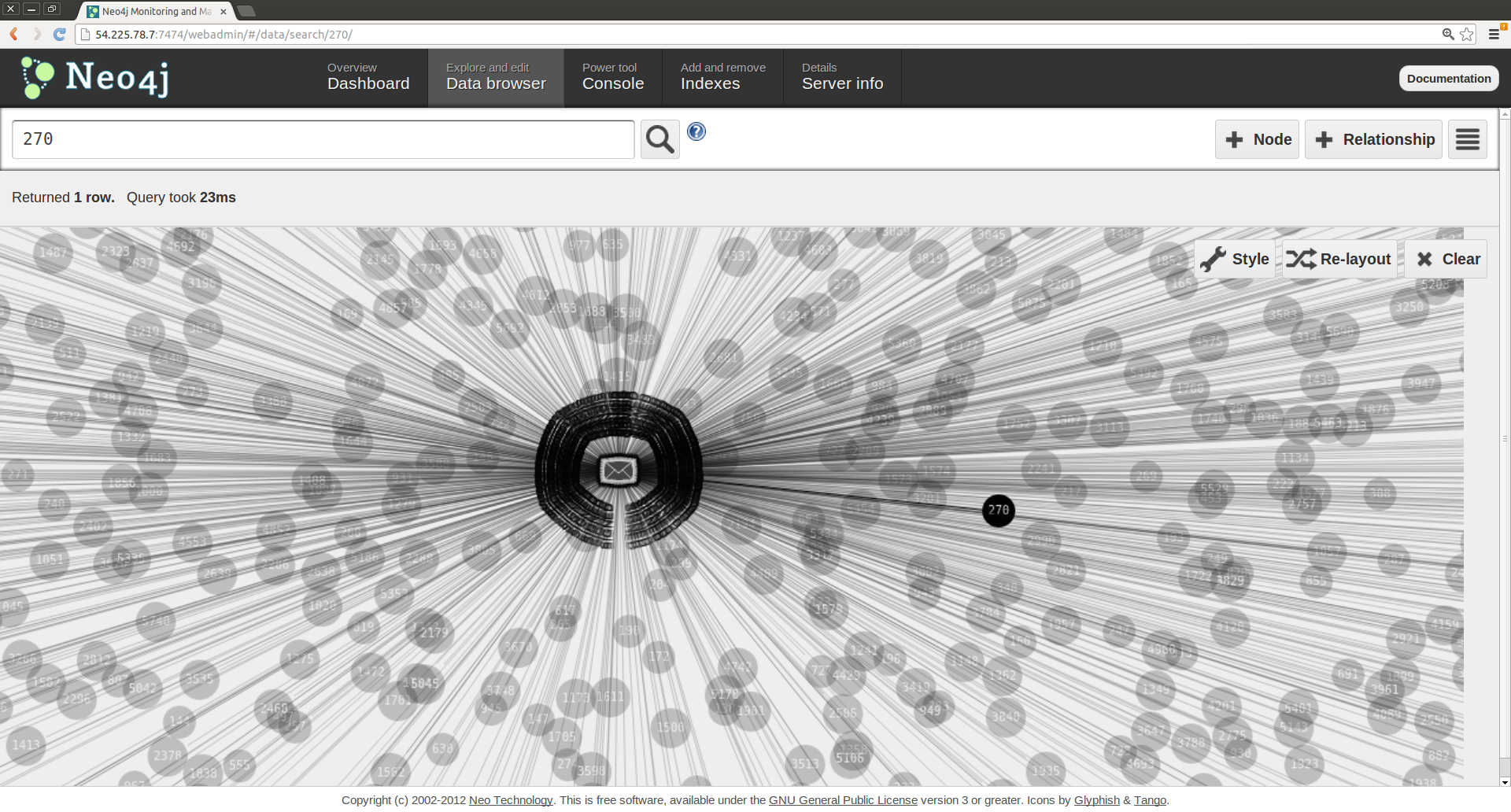
Once imported in Neo4j, a user could ask questions such as:
- Given petition X, find all other petitions signed by the same people
- Given signator X, find all co-signators of any number of petitions
Given that the signator is partially anonymized (only initials and sometimes zip codes), the answers to these questions can’t be settled definitively. Still, given the large amount of data available, some interesting patterns might be identified and analyzed.
Inspired by the group effort, Professor Chaiken continued after hours working on a C-language parser for the petitions data.
All in all, the day was productive, entertaining, and educational. A pleasant time was had by all and good friendships were founded and strengthened.
 At the end of the day, determined Civic Hackers Tim Fake, Dima Kassab, and
At the end of the day, determined Civic Hackers Tim Fake, Dima Kassab, and
Seth Chaiken lowered the banner with a feeling of accomplishment.
Pictures of the Event Nationwide can be seen here:
http://www.flickr.com/groups/hackforchange
http://www.hackforchange.org/albany-ny-national-day-civic-hacking