New in ParaView: Coloring by field data

In some situations, you may have a single data value associated with a data set that you would like to visualize “on” the data set. For example, you may want to visualize a boundary condition parameter defined for each surface in a computational fluid dynamics simulation. ParaView 4.3 now makes that possible.
You can now color data sets in ParaView by the value of a tuple in a field data array associated with the data set. Field data arrays in a data set now appear in the list of data arrays available to select for coloring. If a field data array is chosen, the first tuple in the array will be used to determine the color of the entire surface of the object being visualized. Tuples may have more than one component, in which case a specific element of the tuple can be selected (similar to how X, Y, or Z components can be selected for vectors) or the magnitude of the tuple can be selected instead.
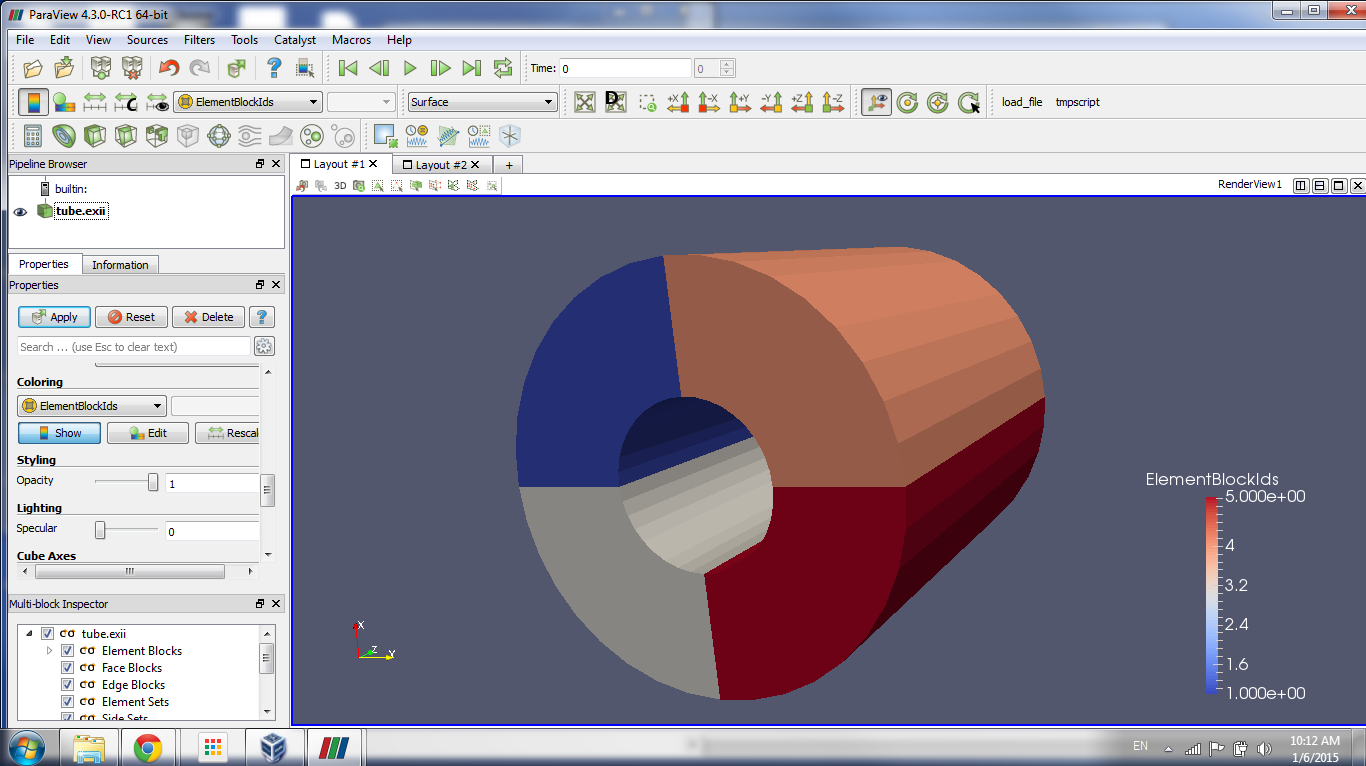
Coloring by field data also works when you have a composite data set where each member data set has a field data array with the same name. As an example, consider the ParaView example data file tube.exo (available to download here). It is a multiblock data set containing four blocks. Each block has a field data array named “ElementBlockIds” that has one element with the block ID. If you select the “ElementBlockIds” array to use for coloring the data, each block will be colored by the element block ID associated with that block.