
New Infrastructure for Easy Multi-threading in ITKv4

Previous Infrastructure
In the context of multi-threading, image processing is often considered an “embarrassing parallel” problem. That is, since the operations to create one output pixel are often independent from other output pixels, data-parallelism can be achieved when output pixels are partitioned into sub-domains to be processed in each thread.
Infrastructure to easily write multi-threaded itk::ImageToImage filters has been available for a long time, and the majority of image processing code in ITK can take advantage of parallel computing architectures. While embarrassing parallel problems may make the design of a parallel algorithm obvious, multi-threaded code is often not realized until there exists sufficiently high-level abstractions that remove the need to learn low-level details, write verbose boilerplate code, and debug the results. Recently, APIs such as OpenMP provide these abstractions in a cross-platform way. ITK also has a cross-platform API for the creation of multi-threaded code, but its design is more appropriate for image analysis in a C++, generic programming context than OpenMP.
To write multi-threaded code with the traditional itk::ImageSource API, a filter author simply needs to overload select virtual protected methods:
- BeforeThreadedGenerateData()
- ThreadedGenerateData (const OutputImageRegionType &outputRegionForThread, ThreadIdType threadId)
- AfterThreadedGenerateData()
The ImageSource methods BeforeThreadedGenerateData and AfterThreadedGenerateData are optional, single-threaded methods to prepare for and respond to the threaded operation. These methods are used to pre-process inputs or handle thread-local storage, for example. After the ITK multi-threading infrastructure spawns threads in a cross-platform way, the ThreadedGenerateData method will be called in each thread.
In the ITKv4 effort, additional infrastructure was added that improves the multi-threaded operation flexibility within image filters, and also makes it possible to easily write multi-threaded code outside of itk::ImageToImageFilters. This infrastructure is used extensively in the v4 registration metrics and v4 level set evolution code.
Improved Method Flexibility
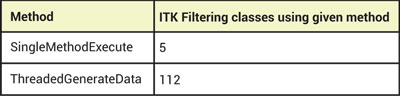
While the traditional BeforeThreadedGenerateData/ThreadedGenerateData/AfterThreadedGenerateData infrastructure covers the majority of image filtering algorithms, not all filters conform to this model. For example, an image filtering algorithm that is organized into a single unit should be logically organized into a single C++ class in its source code, but it may contain multiple parallelizable operations that must be separated by serial operations. In the past, this situation required the use of thread synchronization classes or resorting to the use of verbose, low-level threading code. In practice, this meant that multi-threading was not achieved in these cases. This is evident in the table below where the number of classes in the ITK 4.3 Filtering Group that use the low-level SingleMethodExecute call are compared to the number of classes that use the high-level ThreadedGenerateData.
Code for reproduction:
cd Modules/Filtering
git grep -l SingleMethodExecute\(\) | wc -l
git grep -l ::ThreadedGenerateData | wc -l
Another limitation is that ITK is a registration and segmentation library in addition to image an image filtering library, and most registration and segmentation classes do not inherit from itk::ImageSource, so ThreadedGenerateData is not available.
In the new ITKv4 infrastructure, high-level multi-threaded operations are written not by overloading a particular virtual method (ThreadedGenerateData), but by adding a new member class that inherits from itk::DomainThreader. This has a number of advantages. High-level, multi-threaded operations can be applied in any class, not just those that inherit from itk::ImageSource. An algorithm that has multiple, multi-threaded operations can be organized into a single C++ class by simply adding more than one itk::DomainThreader member. Within a GenerateData call, the class members can be called in any order, repeatedly or conditionally, as necessary. All the state variables related to the threading operation will be appropriately encapsulated as members of the itk::DomainThreader derived class.
The itk::DomainThreader class is templated over the type of data domain it is going to partition (described below) and the type of the class that it will be performing the threaded operation for, known as the “Associate” class. When an Associate class declares an itk::DomainThreader member, it typically uses the C++ “friend” keyword so the Associate class has access to its protected and private members.
Similar to the traditional BeforeThreadedGenerateData / ThreadedGenerateData / AfterThreadedGenerateData methods, implementation of a threaded operation with itk::DomainThreader consists of implementation of its BeforeThreadedExecution, ThreadedExecution / AfterThreadedExecution.
Improved Domain Support
In the traditional multi-threading infrastructure, the itk::Image data was partitioned by splitting the output itk::ImageRegion into a contiguous, non-overlapping sub-domain itk::ImageRegions. In the new infrastructure, a new class, itk::ThreadedDomainPartitioner, provides the abstraction so that many different types of domains can be partitioned into sub-domains to be processed in each thread. Currently, an itk::ThreadedImageRegionPartitioner is implemented along with an itk::ThreadedIndexedContainerPartitioner and an itk::ThreadedIteratorRangePartitioner. The itk::ThreadedIndexedContainerPartitioner will split up a container that is indexed by integers, such as an itk::Array. The itk::ThreadedIteratorRangePartitioner will partition itk or STL iterator ranges into sub-ranges to be processed in each thread.
 Future Improvements
Future Improvements
Further information can be found on ITKBarCamp [1] and ITKExamples [2].
[1] http://insightsoftwareconsortium.github.com/ITKBarCamp-doc/ITK/WriteMultiThreadedCode/index.html
[2] http://itk.org/ITKExamples/Examples/Core/Common/DoDataParallelThreading/DoDataParallelThreading.html
With the current ITK threading backends, parallelization will not necessarily improve algorithmic performance. In practice, overhead associated with spawning and joining threads to perform threaded operations can easily overshadow the time required to perform the operation itself. Therefore, adoption of a threading pool infrastructure in ITK could greatly improve multi-threading performance.
Acknowledgements
The ITKv4 effort was made possible by funding from the American Recovery and Reinvestment Act (ARRA) via the US National Institutes of Health (NIH) National Library of Medicine (NLM).
Additional authors who contributed to this article include Dr. Brian B. Avants, Michael Stauffer, and Baohua Wu at the University of Pennsylvania; Nicholas Tustison at the University of Virginia; and Dr. Arnaud Gelas of Crisalix SaaS.
 Matthew McCormick is a medical imaging researcher working at Kitware, Inc. His research interests include medical image registration and ultrasound imaging. Matt is an active member of scientific open source software efforts such as the InsightToolkit, TubeTK, and scientific Python communities.
Matthew McCormick is a medical imaging researcher working at Kitware, Inc. His research interests include medical image registration and ultrasound imaging. Matt is an active member of scientific open source software efforts such as the InsightToolkit, TubeTK, and scientific Python communities.