Running ParaView on a Supercomputer

Data migration is a well-known bottleneck in high-performance computing (HPC). A user’s desktop or local storage will never have the capacity of the supercomputer on which a simulation is originally run. So, why not use the supercomputer itself for visualization? Computing centers around the world have done this for a few years. But, until now, the rendering task was completed with software (Mesa) rendering.
Enabling graphics processing unit (GPU) rendering on the Cray is the challenge set by members of the staff at the Swiss National Supercomputer Centre (CSCS), which is home to one of the largest GPU installations in the world. “Piz Daint,” our lead supercomputer, is a 28-cabinet Cray XC30 system with a total of 5,272 compute nodes. It is ranked sixth on the list of fastest supercomputers [1]. Each node is equipped with an eight-core 64-bit Intel SandyBridge CPU (Intel® Xeon® E5-2670), an NVIDIA® Tesla® K20X with 6 GB of GDDR5 memory, and 32 GB of host memory. The nodes are connected by the “Aries” proprietary interconnect from Cray, with a dragonfly network topology.
Graphics on the Cray Node
The biggest challenge of running ParaView on a Cray node is that we have a stripped-down version of a Linux kernel. Compute nodes were never thought to be used for running X-Windows-based applications. Enabling visualization on the node would not only mean that we could do GPU-accelerated graphics, but it would also take advantage of the great hardware support that differentiates a supercomputer from a cluster, i.e., ultra-fast input/output (I/O) from our LUSTRE file system and a node interconnect fabric optimized for inter-node data exchange.
Switching the GOM to Enable Graphics
By default, the Cray installation had all GPUs set with their Operation Mode (GOM) as “Compute.” This disables graphics features to optimize compute tasks. As “Compute” is a persistent state, rebooting is required to switch the GOM to “All on,” enabling graphics. After a temporary period during the summer of 2014, when we reserved a small partition of 128 nodes to test out the “All on” feature, we switched all 5,272 GPUs to “All on,” maintaining reliability across the whole machine. This was initiated after our test demonstrated an insignificant increase in power consumption.
Compiling an X Server for the Node
Compiling Xorg was a task that required multiple trial-and-error procedures. Gilles Fourestey at CSCS led this effort and managed an installation that would enable us to run X-Windows applications. Xorg usually relies on the automatic detection of displays, but NVIDIA Teslas do not have displays and, therefore, do not have Extended Display Identification Data (EDID). The solution adopted was to set up Xorg with a headless virtual screen, which was attached to DISPLAY :0.
Job Scheduler Prolog and Cleanup
Visualization jobs remain non-standard on the machine. Thus, the X server is only started on demand when our job scheduler makes the request for a set of nodes to run ParaView’s pvserver or pvbatch applications. We use SLURM’s –constraint option to launch X a few seconds before launching ParaView. On return, SLURM executes a cleanup sequence to free up the GPU from the excess baggage.
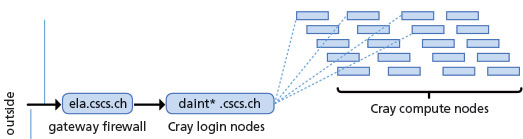
ParaView in Client-Server Connections from the Outside
Our computing center is protected behind a firewall, which is the only point of entry. From this gateway, the user can Secure Shell (SSH) to the login nodes of the Cray. Note that pvservers actually run on the compute nodes. We have not enabled the QT-based GUI part of ParaView in order to refrain from overloading the login nodes and to enforce the use of optimized pixel transfers between ParaView’s client and pvserver tasks. We opted to use a reverse connection mode to connect outside clients to the Cray. To enable this, the pvserver tasks launched on the compute nodes must have a way to connect back on the SSH tunnels established between the user’s desktop, the firewall, and the login node responsible for submitting the SLURM job.
For this to work, the login nodes are set to enable GatewayPorts=yes in their sshd_config files. We have multiple login nodes, all answering to the address “daint.cscs.ch” to ensure proper load balancing. Due to such round-robin load balancing, we quickly figured out that the compute nodes were not guaranteed to listen to the correct SSH tunnels created with the standard address. Thus, we have dedicated one such login node for ParaView jobs. We document here the specific commands used to connect from the outside and launch ParaView.
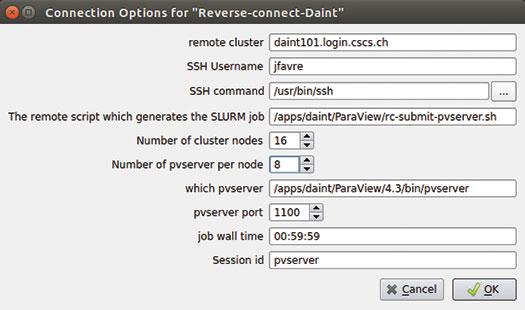
The user is presented with the dialog shown below. We require each user to connect to a unique port ID, equal to his or her user ID, such that the selected login node can serve multiple requests to open SSH tunnels for different users.
Linux Users
The dialog above creates a launch command with the following format:
/usr/bin/ssh -l jfavre -R 1100:localhost:1100 daint101.login.cscs.ch /apps/daint/ParaView/rc-submit-pvserver.sh pvserver 00:59:59 16 8 /apps/daint/ParaView/4.3/bin/pvserver 1100 daint101.login.cscs.ch; sleep 360
This command does the following.
- It creates a tunnel on port 1100 (my user ID) to the login node “daint101.login.cscs.ch”
- It passes multiple arguments to a shell script running on the login node, which itself creates and submits a SLURM job, requesting 16 nodes, 8 tasks per node, and 16 GPUs
- The X server is then started on the allocated nodes
Note that allowing an SSH command from the user’s desktop to directly access the Cray login node through the firewall requires a connection proxy. This is accomplished with the following code in the user’s $HOME/.ssh/config:
Host daint*.cscs.ch
ForwardAgent yes
Port 22
ProxyCommand ssh –q –Y jfavre@ela.cscs.ch
netcat %h %p –w 10
We added a sleep command to give the compute node time to connect itself to the tunnel. Once started, the pvserver MPI job is run with Cray’s aprun command:
aprun –n 128 –N 8 /apps/daint/ParaView/4.3/bin/pvserver –rc –ch=daint101.login.cscs.ch –sp=1100 –disable-xdisplay-test
Windows Users
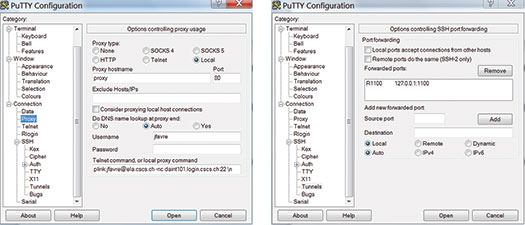
For Windows users, the syntax of the launch command to create the tunnel and access the login node is a bit more complicated and requires creating a PuTTY profile.
Our computing center users are instructed to implement the following procedure.
- Create an SSH key, and install it in pageant to enable password-less access to the login node
- Create a PuTTY profile to set up the reverse tunnel
We distribute a *.reg file, which each user has to modify just slightly with his or her username and user ID. The PuTTY Connection proxy uses Plink to forward the request for connection from the firewall to the Cray login node:
plink jfavre@ela.cscs.ch –nc daint101.login.cscs.ch:22 \n
The SSH tunnel creates a remote forward port to the localhost. (Recall that my user ID is 1100.) For example:
We are good to go. The Windows ParaView client now creates a slightly different launch command. Assuming the PuTTY profile has been named “ParaView-Reverse-Connect,” the command issued is:
“C:\Program Files (x86)\PuTTY\plink.exe” -l jfavre daint101.login.cscs.ch –load ParaView-Reverse-Connect /apps/daint/ParaView/rc-submit-pvserver.sh pvserver 00:59:59 16 8 /apps/daint/ParaView/4.3/bin/pvserver 1100 daint101.login.cscs.ch; sleep 360
Applications
GPU-enabled rendering allows us to render large geometries at interactive speed. It also enables a range of display options, which contribute greatly to an improved visual perception. Examples include increased realism with silhouette edges (thanks to the EyeDome Lighting plugin). The following two pictures show a close-up look of a dense polygonal object, with (right) and without (left) silhouette edges.

The proper ordering for transparent surfaces obtained with depth peeling also makes quite the difference to disambiguate surface ordering, as seen in the next example in molecular science. Compare the two images, and look for the rendering artifacts in the left-hand picture created without depth peeling.
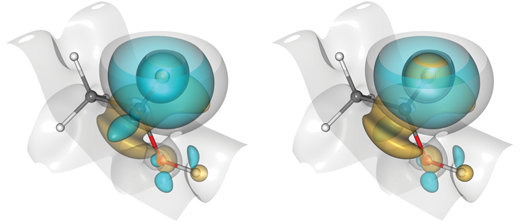
A molecular assembly is shown with atoms and bonds, as well as isosurfaces representing electron density. Rendering artifacts (left) are due to an improper composition of transparent surfaces. Proper rendering is achieved with depth peeling (right).
Another hardware-enabled plugin is the Linear Integral Convolution (LIC) display representation [2]. The left-hand image shows how difficult it can be to represent the shear stress on a polygonal surface because of pathological numerical conditions. Displaying a dense image with LIC is of great help. (See the right-hand image.)

Displaying particle data from astrophysics simulations can also be accomplished with Point Sprite rendering on the GPU. This is yet another example that could not have been done on the Cray using traditional Mesa-based rendering.
Summary
Providing GPU rendering on the Cray supercomputer at CSCS enables our users to run ParaView with the best overall hardware resources, including the best I/O, the fastest interconnect, and the most advanced GPU rendering. We provide them with a point-and-click interface to establish remote connections from their desktops to our leadership Cray supercomputer. ParaView is integrated with the job scheduler to request all hardware and software resources necessary (GPUs and X server launches). Job chaining is enabled, allowing our users to directly pipe the output of simulations to ParaView’s pvbatch for automatic post-processing with headless GPU rendering. Moving forward, we already have ParaView version 4.3 enabled with the OpenGL2 backend. This allows for rendering that is orders of magnitude faster for some models, even though not all of the plugins mentioned above are currently enabled. Another point on our radar is the use of EGL. Kitware recently announced its collaboration with NVIDIA, which will add future EGL support to its drivers, eliminating the need to install an X server for graphics output in ParaView [3]. This will enable a more streamlined deployment in architectures such as Cray supercomputers, where the X server software stack is not readily available.
Acknowledgements
At CSCS, Gilles Fourestey was responsible for the entire compilation of X, while Nicola Bianchi and Fabio Verzelloni contributed to the deployment, testing, and job scheduler issues. Chris Gamboni (CSCS network admin) contributed to the delicate interplay of SSH tunnels and PuTTY configuration. Utkarsh Ayachit at Kitware provided a launch sequence, which smoothed out the difficulties we had on the Cray. He added a –disable-xdisplay-test pvserver option.
References
[1] http://www.top500.org/list/2014/11/
[2] http://www.paraview.org/Wiki/ParaView/Line_Integral_Convolution
[3] http://www.kitware.com/news/home/browse/563?siteid=8

Jean M. Favre is the Visualization Task Leader at the Swiss National Supercomputer Centre (CSCS) in Lugano, Switzerland.