Continuous Integration in the Azure Cloud with CDash and Jenkins

Testing in the Cloud
The flexibility of cloud computing platforms can be leveraged to provide scalable continuous integration testing. Using cloud computing resources effectively, however, requires the coordination of a robust software infrastructure.
When a developer on a large open-source project finishes a draft of a patch, he or she should not have to wait for the next day’s build to see whether it breaks anything. This project aims to provide quick feedback on Gerrit (a Web-based Git review system) patches, based on results from builds on multiple platforms, through the CDash quality software dashboard. While we used the Microsoft Azure Cloud for our computing resources, the methodology remains the same across any cloud computing service.
CDash [1] is an open-source Web server that aggregates, analyzes, and visualizes results of software build and testing systems. CDash works particularly well with the CMake and CTest build and testing configuration systems. Cross-platform builds and tests configured with CMake scripts are executed with CTest scripts, and the results are uploaded to CDash.
The open-source Jenkins continuous integration server is used to schedule and coordinate builds. Its base system can be extended with a number of plugins created by the vibrant Jenkins community. One available open-source plugin is the Azure Slave Plugin, which spawns, destroys, and manages virtual machine build slaves on the Microsoft Azure Cloud.
Another available Jenkins plugin is the Gerrit Trigger plugin, which integrates Jenkins with the Gerrit Code Review system. In the following sections, we describe how CDash, Jenkins, and Gerrit were integrated to generate a visual display of build and test results for proposed patches to the Insight Toolkit (ITK). ITK is a powerful, cross-platform toolkit for the processing, segmentation, and registration of N-dimensional images.
Preparation of Cloud Virtual Machines
Builds occur on virtual machines in the cloud, which are prepared for dynamic instantiation and destruction. A virtual machine (VM) image (e.g., a VM template) can be stored without use of compute resources and can be created from the base images available on the Azure cloud. Both Windows and Linux base images can be enhanced with the required build resources.
Required build tools and dependencies should be installed on the VMs. For ITK, this includes CMake, a C++ compiler, and Git. Since ITK uses the Git distributed version control system, and it is a large project with a long history, a new clone of the source code repository for every build would require extensive time and network resources. A clone of the source code repository on the template image disk can be used by a Jenkins initiated build as a reference repository. Accordingly, only changes made since the creation of an image must be downloaded.
ITK also uses an ExternalData object store [2] to reference and retrieve testing data. A cache of this testing data is downloaded to the testing image. Finally, since the VMs will be controlled as build slaves by Jenkins, a Java runtime should be installed on the VM.
After the required resources are installed on the VM instance, a template image is created in the Azure Cloud following Azure’s documentation. One or more new Azure slaves can be configured from this image template in Jenkins’ configuration, as seen in Figure 1. The VM size, which determines the number of cores and the amount of memory allocated to the VM, does not necessarily need to correspond to the size of the VM instance used to create the template image.
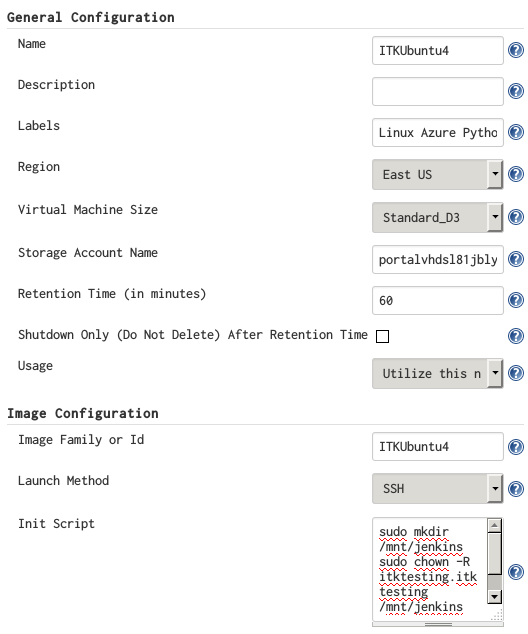
Figure 1: Jenkins Azure slave configuration.
If Jenkins requests a new build, and labels (tags) for the image template match the requested build labels, a new instance will be spun up from the template. A retention time, which defaults to 60 minutes, can be specified for the image. After the build is executed, the instance will remain available for the retention time, waiting for new builds. If no new builds are requested, the VM instance is shutdown or deleted, i.e., the slave is put in a state that does not require computational resources.
New storage resources are provided for the VM hard drives when created. The Azure Linux VMs receive a 30 GB partition for root by default and a much larger partition mounted at /mnt. However, the larger partition is not persistent. Therefore, supporting resources should be installed into the root partition and the Jenkins build workspace should be configured on /mnt. An Init Script, which is run at VM instantiation, can be used for operations like the creation of the workspace directory.
Configuration of Builds
CTest performs cross-platform tests and works well with CMake-configured builds. While CTest scripts are written in the same scripting language as CMake scripts, special commands are available to run different stages of the testing process. These commands include ctest_update, ctest_configure, ctest_build, ctest_test, and ctest_submit, which update the source code repository, configure the build, build the software, run the unit tests, and submit the results of the process to the CDash Web dashboard, respectively.
Many projects, including ITK, have one common CTest script that runs all the commands of the testing process. The script can be modified with variables that define the specifics of a build machine or a build configuration.
To configure CTest-driven builds on the Jenkins scheduler, we used the Config File Provider Jenkins plugin. This plugin makes it possible to create and manage configuration files in the Jenkins interface and then add them to a build. Many files are created and then mixed-and-matched to create an individual build configuration. The files are named XX-<DescriptiveName>CTestConfig.cmake so that they can be included in a known order. For example, the file 21-ReleaseCTestConfig.cmake contains the content set(CTEST_BUILD_CONFIGURATION Release) to specify a Release, as opposed to a Debug, build configuration.
The CTest script used with Jenkins includes the contents of these configuration files. The script passes build information exported by Jenkins in environmental variables, such as the build workspace path, to CTest. Finally, the script includes the common CTest script. The scripts are stored in the dashboard branch of the project’s source code repository.
A typical Jenkins build command only contains three steps. First, the directory used to hold the CTest scripts in removed. This directory is then repopulated with a fresh clone from the upstream repository dashboard branch. Since the dashboard branch has a separate history from the main repository, its download is small and fast. This process ensures that all builds run from the latest build scripts. The last step is to run the CTest script. We ensure that the script execution returns non-zero if the configuration process fails, if build errors or warnings occur, or if any of the tests fail. Jenkins uses this result to determine if a build was a failure or success.
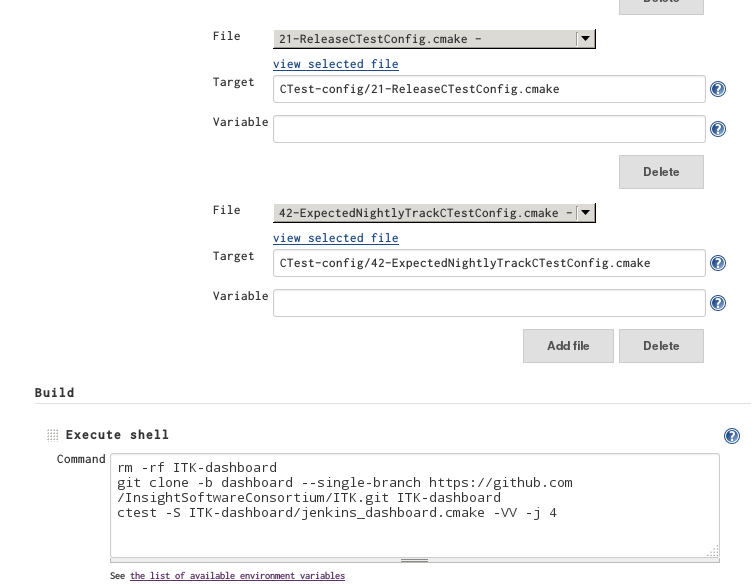
Figure 2: Options for a build are specified through CTest script configuration files (top). The Jenkins build command consists of a fresh clone of the dashboard scripts and a Ctest execution of the dashboard script.
Connecting CDash, Jenkins, and Gerrit
CDash Web visualization, Jenkins build scheduling, and Gerrit code review are connected in multiple ways. To connect Jenkins with CDash, a hyperlink to the CDash visualization of a given build can be generated. With the Description Setter Jenkins plugin, a regular expression that detects and extracts the CDash Build Identifier output line can create a custom CDash query that filters for a given build.
To ensure that Jenkins cloud builds are organized into their desired group within the CDash project page, the TRACK option to the ctest_start command will direct a build to its appropriate group. Finally, the Gerrit Trigger Jenkins plugin will spawn builds for proposed patches pushed to Gerrit. Since the builds are named by their Gerrit patch identifiers, a link to the CDash filtered build page is created in the Jenkins-generated Gerrit patch comments.

Figure 3: Jenkins load statistics versus time.
Figure 3 shows running executors (blue), busy executors (red), and build queue length (gray). At the point marked by the arrow, the gap between running executors and busy executors decreases. This indicates better resource efficiency.
Conclusions
Cross-platform builds for proposed software patches are critical for maintaining software quality, especially for large, collaborative, multi-platform projects. On-demand cloud computing builds that efficiently use computational resources and scale to dynamic load are possible. However, complex software tools are required to schedule builds and to communicate their results.
In this article, we described how three high-quality, open-source software tools can be combined to perform continuous integration testing in the Azure cloud. We found that CDash for result visualization, Jenkins for build scheduling, and Gerrit for code review work nicely together. In the future, this integration process could be streamlined and standardized with a Jenkins plugin for CTest scripts.
Acknowlegements
Testing of the Insight Toolkit on the Azure Cloud was made possible by an award from the Microsoft Azure Research Award Program. Maintenance of the Insight Toolkit was supported by the National Library of Medicine ITKv4 Help Desk Contract HHSN276201300003I.
References
[1] www.cdash.org
[2] CMake ExternalData: Using Large Files with Distributed Version
Control, http://www.kitware.com/source/home/post/107

Matthew McCormick is a medical imaging researcher working at Kitware. His research interests include medical image registration and ultrasound imaging. Matthew is an active member of scientific open-source software efforts such as the Insight Toolkit, TubeTK, and scientific Python communities.

Bill Hoffman is vice president and CTO of Kitware. He is a founder of Kitware and a lead architect of the CMake cross-platform build system. Bill is involved in the development of the Quality Software Process and CDash, the software testing server.

Christopher Mullins is a software engineer at SonoVol, LLC, developing applications for robotic 3D imaging with ultrasound.

Hans Johnson is an associate professor of electrical and computer engineering at the University of Iowa. His primary research interest involves accelerating research discovery through the efficient analysis of large scale, heterogeneous, multi-site data collections using modern HPC resources.